一、前言
各位ks社区前辈大佬们好,Kubesphere 投入生产项目已有半年之久,目前在日志收集这块出现一些列问题,关于该问题社区一位大佬前辈昨日给我提供了一个参数配置,但无奈该问题未得到解决,因此重新发贴求助各位前辈。万分感谢附上,上篇帖子链接(https://ask.kubesphere.io/forum/d/22968-kubesphere-ping-tai-wu-fa-zheng-chang-shou-ji-ri-zhi-fluent-bitri-zhi-bao-cuo-wu-fa-zeng-jia-huan-chong-qu/9)
kubesphere版本:基于k8s最小化部署的3.3.1版本
Kubernetes 版本:1.22.0

二、问题描述
Kubesphere平台投入生产运行一段时间之后,研发反馈Kubesphere生产以及测试平台都无法展示日志,搜索日志都是空白,如下图所示

于是乎,着手开始排查定位具体问题,发现fluent-bit 容器日志一直在报错,具体错误如下
[2023/07/23 00:15:37] [ warn] [http_client] cannot increase buffer: current=512000 requested=544768 max=512000
{"log":"[2023/11/08 10:26:33] [ warn] [input] tail.2 paused (mem buf overlimit)\n","stream":"stderr","time":"2023-11-08T10:26:33.406030339Z"}

根据上述的错误信息可以看出是需要调整内存缓冲区大小(memBufLimi)以及缓冲区大小(Buffer_Size)相关参数,我分别在CDR->input->tail 定义" memBufLimit" 以及在CDR->es定义 ”bufferSize“.


以上操作之后,于是乎尝试重启Fluent-bit 服务使其修改之后的参数生效,就在我满怀欢喜等待,日志平台恢复正常,新的噩耗出现了,Fluent-bit有出现了新的错误,如下所示:
[2023/12/04 23:17:16] [error] [http_client] broken connection to elasticsearch-logging-data.kubesphere-logging-system.svc:9200 ?
[2023/12/04 23:17:16] [ warn] [output:es:es.0] http_do=-1 URI=/_bulk
[2023/12/04 23:17:16] [error] [http_client] broken connection to elasticsearch-logging-data.kubesphere-logging-system.svc:9200 ?
[2023/12/04 23:17:16] [ warn] [output:es:es.0] http_do=-1 URI=/_bulk
[2023/12/04 23:17:16] [error] [http_client] broken connection to elasticsearch-logging-data.kubesphere-logging-system.svc:9200 ?
[2023/12/04 23:17:16] [ warn] [output:es:es.0] http_do=-1 URI=/_bulk
[2023/12/04 23:17:16] [error] [http_client] broken connection to elasticsearch-logging-data.kubesphere-logging-system.svc:9200 ?
[2023/12/04 23:17:16] [ warn] [output:es:es.0] http_do=-1 URI=/_bulk
[2023/12/04 23:17:16] [ warn] [engine] chunk '12-1701731723.856781118.flb' cannot be retried: task_id=51, input=systemd.1 > output=es.0
[2023/12/04 23:17:16] [ warn] [engine] chunk '12-1701731722.751100596.flb' cannot be retried: task_id=47, input=systemd.1 > output=es.0
[2023/12/04 23:17:16] [ warn] [engine] chunk '12-1701731775.506676822.flb' cannot be retried: task_id=63, input=tail.2 > output=es.0
[2023/12/04 23:17:16] [ warn] [engine] chunk '12-1701731718.465677409.flb' cannot be retried: task_id=36, input=systemd.1 > output=es.0
[2023/12/04 23:17:19] [ warn] [engine] failed to flush chunk '12-1701731835.508401286.flb', retry in 11 seconds: task_id=1, input=tail.2 > output=es.0 (out_id=0)
[2023/12/04 23:17:19] [ warn] [engine] failed to flush chunk '12-1701731836.447435482.flb', retry in 7 seconds: task_id=2, input=tail.2 > output=es.0 (out_id=0)
[2023/12/04 23:17:23] [ warn] [engine] chunk '12-1701731809.214007741.flb' cannot be retried: task_id=5, input=tail.2 > output=es.0
[2023/12/04 23:17:24] [ warn] [engine] failed to flush chunk '12-1701731839.217955696.flb', retry in 7 seconds: task_id=3, input=tail.2 > output=es.0 (out_id=0)
[2023/12/04 23:17:25] [ warn] [engine] chunk '12-1701731814.220947533.flb' cannot be retried: task_id=0, input=tail.2 > output=es.0
从上述错误信息可以看出,主要包括两部分,1. fluent-bit和ES之间的连接断开(这个问题错误可能是我尝试重启fluent-bit发现故障仍未解决,随后又尝试重启ES服务,导致的)2、无法刷新区块这个错误是在修改缓冲区大小“Buffer_Size”之后新的错误信息,更让人崩溃的是,有的fluent-bit pod 仍然报 无法增加缓冲区的错误,如下图所示:

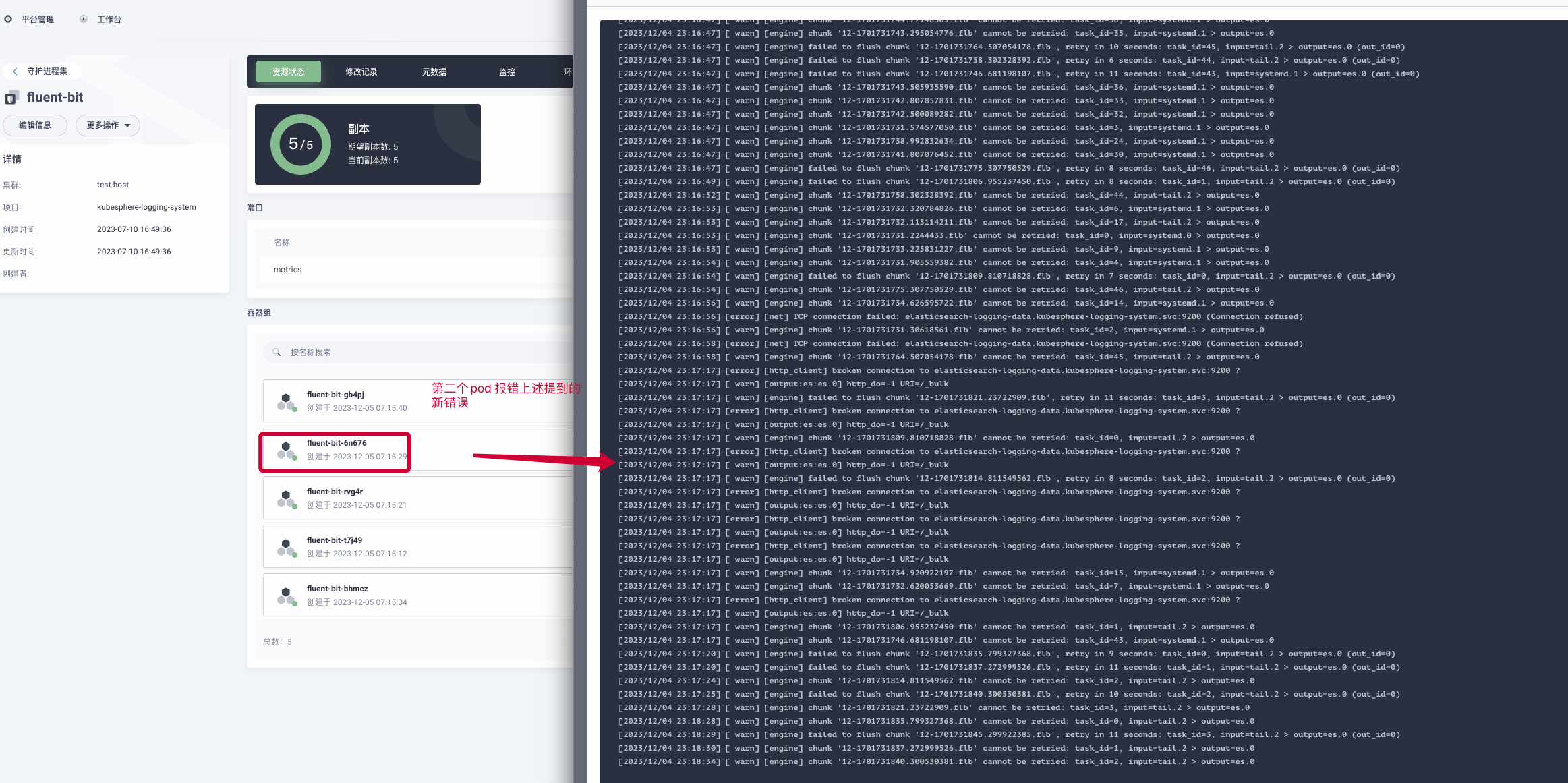
随后根据上述问题,我检查了平台ES是否正常,发现是正常的,面对上述问题,真的很迷茫不知道是哪的问题导致的上述错误,翻阅各种资料文档都未找到相关解决方案,由于是生产项目,影响较为严重,还请社区各位大佬伸出援助之手,帮帮可怜的孩子吧!万分感谢,


