创建部署问题时,请参考下面模板,你提供的信息越多,越容易及时获得解答。如果未按模板创建问题,管理员有权关闭问题。
确保帖子格式清晰易读,用 markdown code block 语法格式化代码块。
你只花一分钟创建的问题,不能指望别人花上半个小时给你解答。
操作系统信息
虚拟机,Ubuntu24.04,master是3台4C/4G,worker是2台6C/16G
Kubernetes版本信息
1.31.3
KubeSphere版本信息
在集群内安装的4.1.2
问题是什么
集群内用helm部署的rook和hive,其中rook用的官方的rook-ceph和rook-ceph-cluster两个chart包,hive用的一个集成了hadoop和hive的chart包,镜像用的自己打包的集成了hadoop、hive、spark、flink的镜像。
在使用rook以前,持久化方案统一用的nfs,hive数据仓库正常运行,说明chart包和镜像本身应该没有问题。
将nfs全面改为ceph后,自动部署了3个storageclass(kubesphere的多个插件都持久化在cephrbd,占用了10个pvc;hive项目持久化在cephfs,占用了4个pvc):
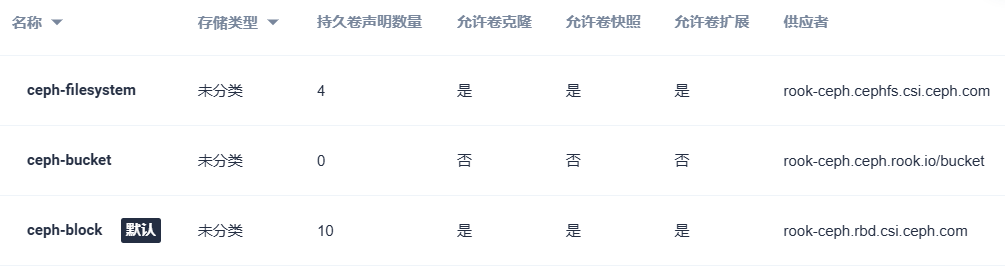
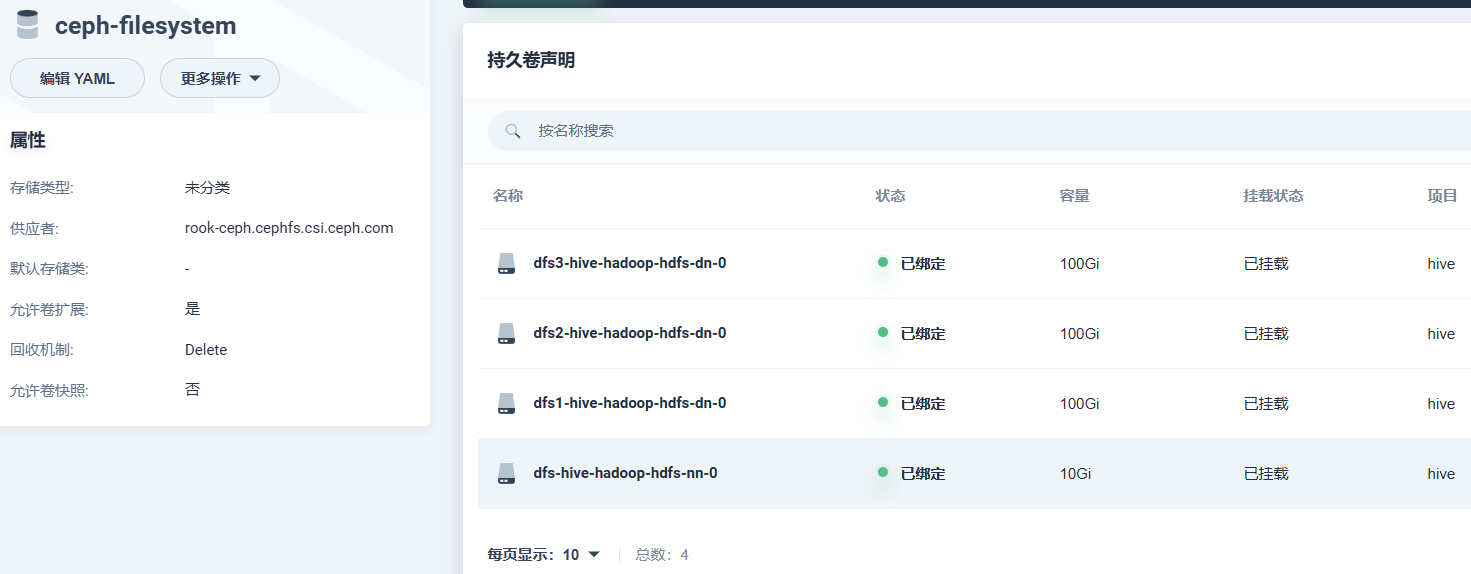
kubesphere的多个插件用的cephrbd,没有发现问题;为了向superset提供hive驱动jar包,手写了一个pod用于把jar包上传到cephfs,删除上传pod后文件还在,后续superset也能正常使用:
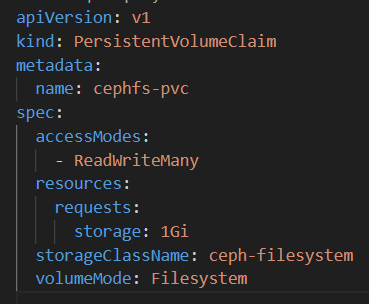

hadoop初始化namenode报错,无法创建所需目录:
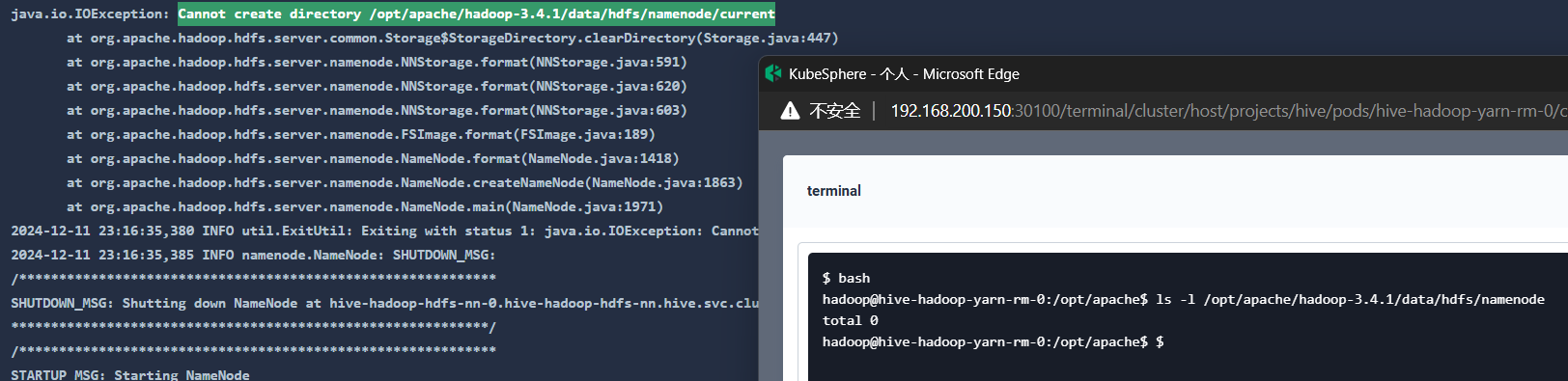

这是hive的configmap:
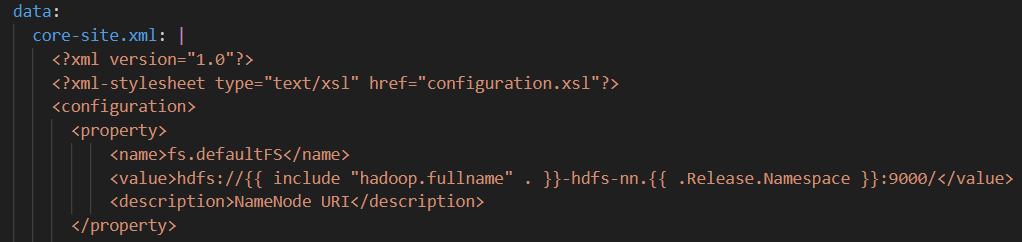

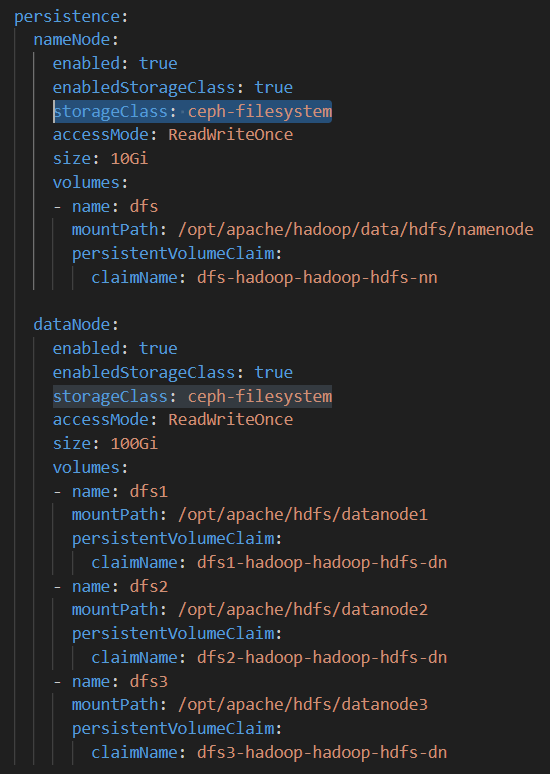
这是hive的values,将两个storageclass从nfs-storage改为ceph-filesystem: