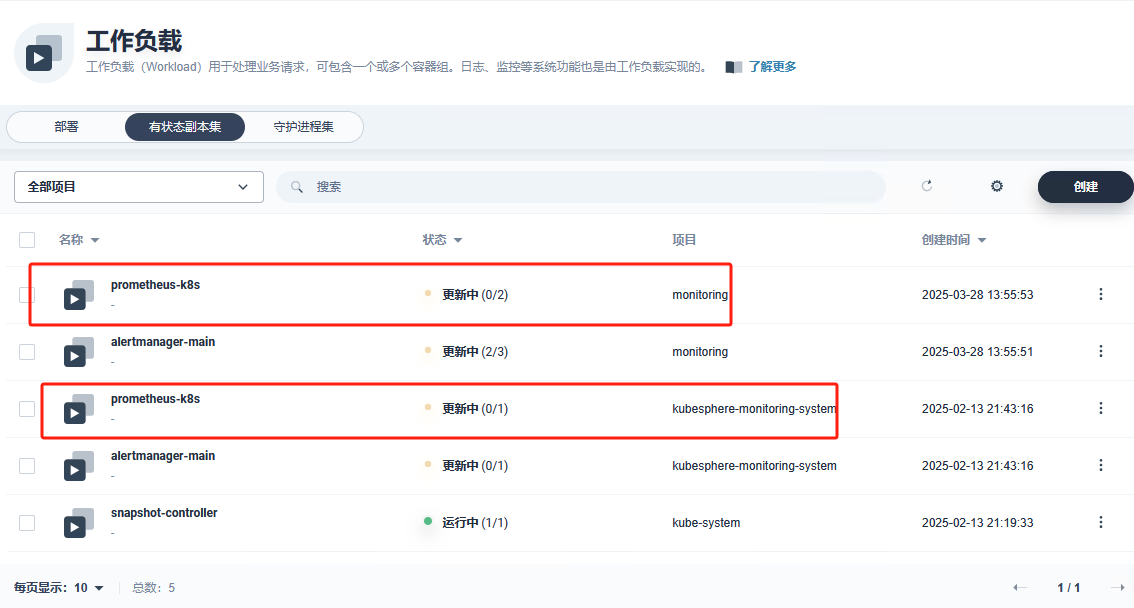
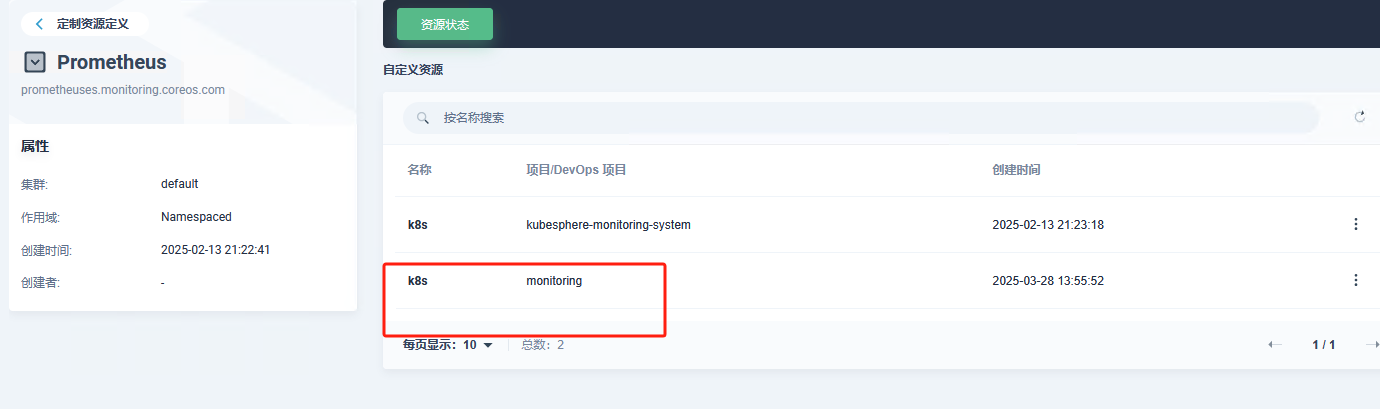
kubesphere版本是v3.4,在现有的kubesphere上已经有了kubesphere-monitoring-system,再部署另一套kube-prometheus到monitoring命名空间,参考的是https://www.qikqiak.com/k8strain/monitor/operator/install/ , 然后完成后发现2个prometheus都处于反复重启中,检查后发现是在CRD Prometheus中有2个不同命名空间的k8s,prometheus可能存在相互冲突,但又定位不到冲突点在哪里,试着改clusterrole,但是不成功。