创建部署问题时,请参考下面模板,你提供的信息越多,越容易及时获得解答。如果未按模板创建问题,管理员有权关闭问题。
确保帖子格式清晰易读,用 markdown code block 语法格式化代码块。
你只花一分钟创建的问题,不能指望别人花上半个小时给你解答。
操作系统信息
例如:虚拟机/物理机,Centos7.5/Ubuntu18.04,4C/8G
Kubernetes版本信息
将 kubectl version 命令执行结果贴在下方
容器运行时
将 docker version / crictl version / nerdctl version 结果贴在下方
KubeSphere版本信息
v1.28.15/v4.1.2。在线安装, 使用kk安装。
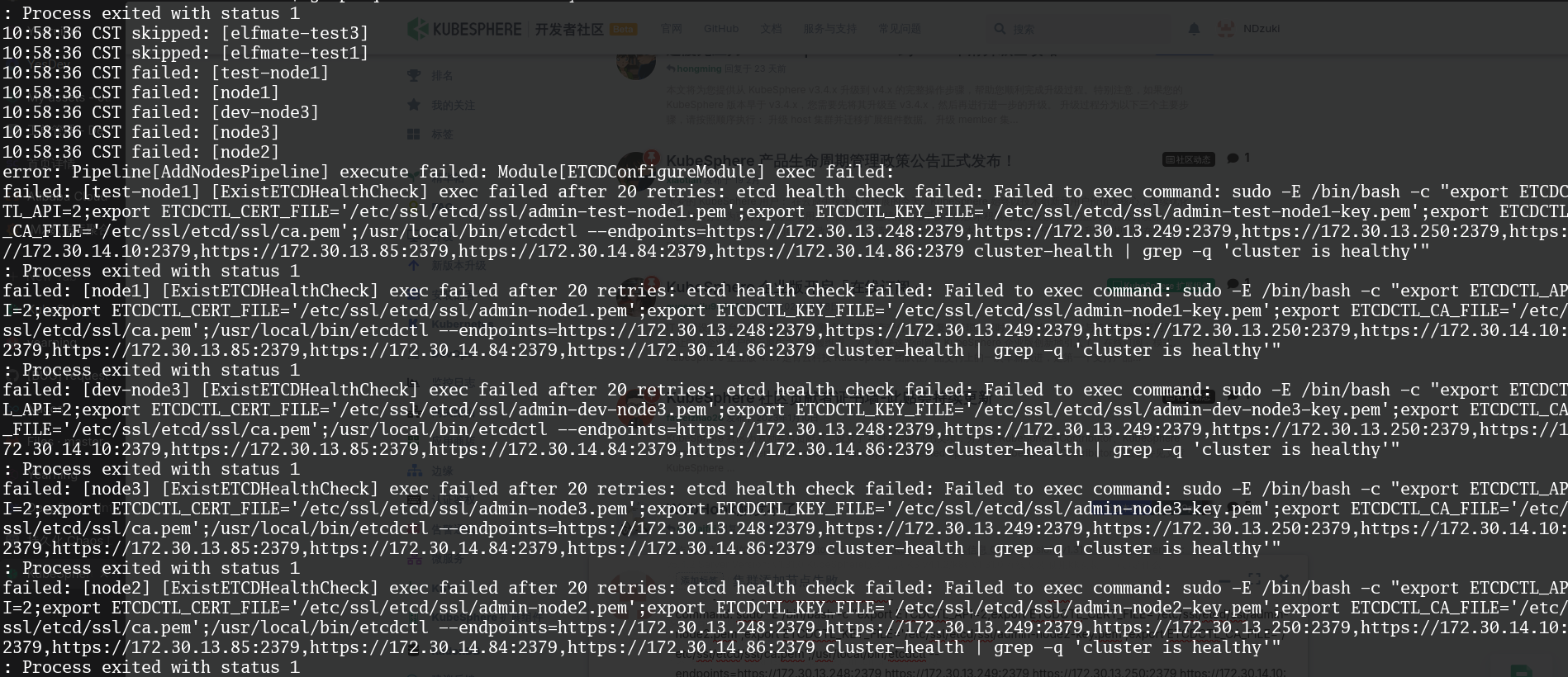
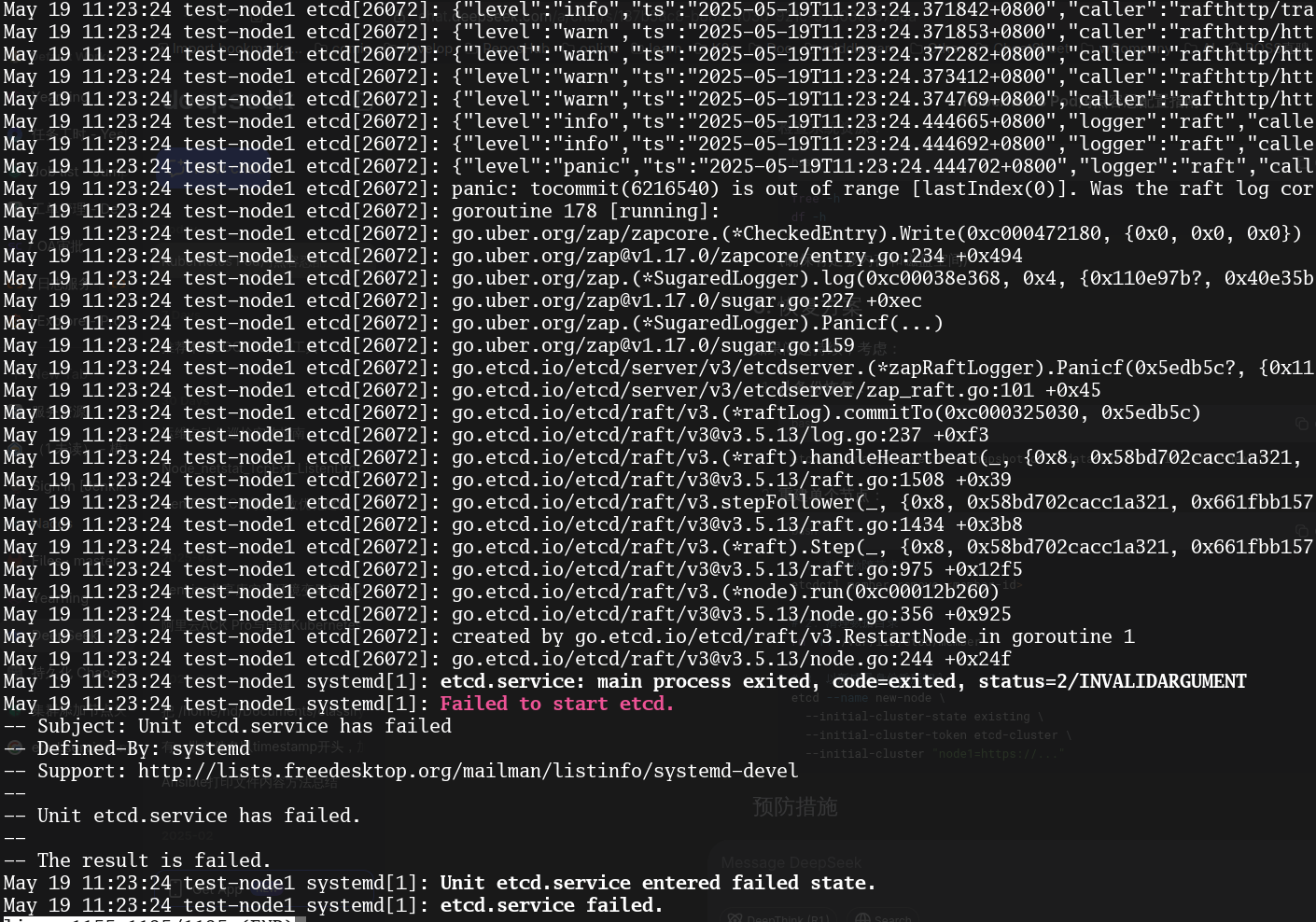
config.yaml增加了新节点,通过 kk add nodes -f config.yaml 直到ETCD检测就失败,重复几次依旧。
error: Pipeline[AddNodesPipeline] execute failed: Module[ETCDConfigureModule] exec failed:
failed: [node2] [ExistETCDHealthCheck] exec failed after 20 retries: etcd health check failed: Failed to exec command: sudo -E /bin/bash -c “export ETCDCTL_API=2;export ETCDCTL_CERT_FILE=‘/etc/ssl/etcd/ssl/admin-node2.pem’;export ETCDCTL_KEY_FILE=‘/etc/ssl/etcd/ssl/admin-node2-key.pem’;export ETCDCTL_CA_FILE=‘/etc/ssl/etcd/ssl/ca.pem’;/usr/local/bin/etcdctl –endpoints=https://172.30.13.248:2379,https://172.30.13.249:2379,https://172.30.13.250:2379,https://172.30.14.10:2379,https://172.30.13.85:2379,https://172.30.14.84:2379,https://172.30.14.86:2379 cluster-health | grep -q ‘cluster is healthy’”
: Process exited with status 1