创建部署问题时,请参考下面模板,你提供的信息越多,越容易及时获得解答。
你只花一分钟创建的问题,不能指望别人花上半个小时给你解答。
发帖前请点击 发表主题 右边的 预览(👀) 按钮,确保帖子格式正确。
操作系统信息
虚拟机,Ubunut
root@sdt:~# cat /etc/os-release
PRETTY_NAME="Ubuntu 22.04.5 LTS"
NAME="Ubuntu"
VERSION_ID="22.04"
VERSION="22.04.5 LTS (Jammy Jellyfish)"
VERSION_CODENAME=jammy
ID=ubuntu
ID_LIKE=debian
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
UBUNTU_CODENAME=jammy
Kubernetes版本信息
K8s 安装版本 1.27.4 单节点。
容器运行时
root@sdt:~# docker -v
Docker version 28.5.1, build e180ab8
KubeSphere版本信息
全套安装。
问题是什么
安装执行到kubeadm的时候就卡住,然后报错
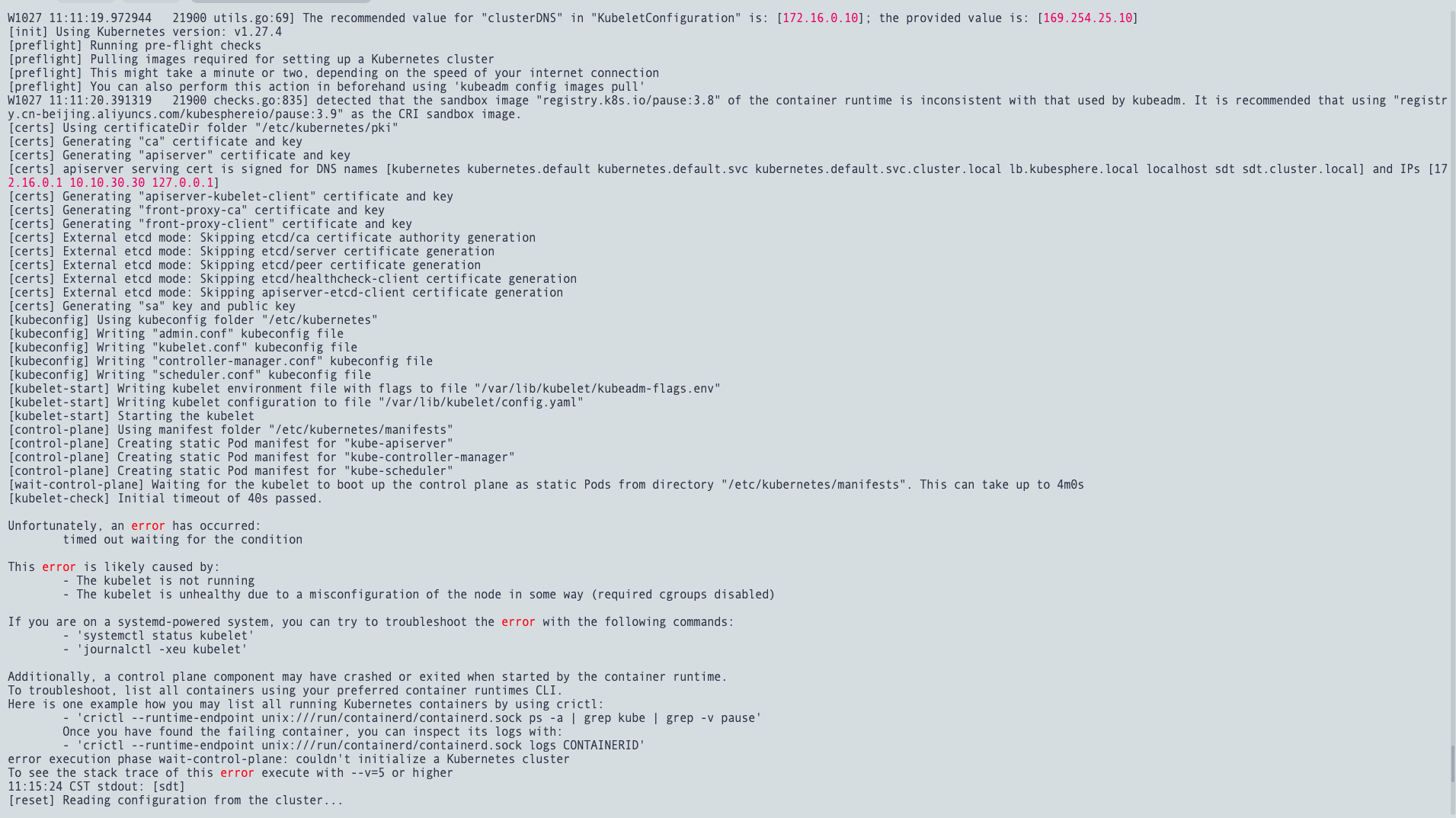
`11:11:19 CST [InitKubernetesModule] Init cluster using kubeadm
11:15:23 CST stdout: [sdt]
W1027 11:11:19.972944 21900 utils.go:69] The recommended value for “clusterDNS” in “KubeletConfiguration” is: [172.16.0.10]; the provided value is: [169.254.25.10]
[init] Using Kubernetes version: v1.27.4
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ‘kubeadm config images pull’
W1027 11:11:20.391319 21900 checks.go:835] detected that the sandbox image “registry.k8s.io/pause:3.8” of the container runtime is inconsistent with that used by kubeadm. It is recommended that using “registry.cn-beijing.aliyuncs.com/kubesphereio/pause:3.9” as the CRI sandbox image.
[certs] Using certificateDir folder “/etc/kubernetes/pki”
[certs] Generating “ca” certificate and key
[certs] Generating “apiserver” certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local lb.kubesphere.local localhost sdt sdt.cluster.local] and IPs [172.16.0.1 10.10.30.30 127.0.0.1]
[certs] Generating “apiserver-kubelet-client” certificate and key
[certs] Generating “front-proxy-ca” certificate and key
[certs] Generating “front-proxy-client” certificate and key
[certs] External etcd mode: Skipping etcd/ca certificate authority generation
[certs] External etcd mode: Skipping etcd/server certificate generation
[certs] External etcd mode: Skipping etcd/peer certificate generation
[certs] External etcd mode: Skipping etcd/healthcheck-client certificate generation
[certs] External etcd mode: Skipping apiserver-etcd-client certificate generation
[certs] Generating “sa” key and public key
[kubeconfig] Using kubeconfig folder “/etc/kubernetes”
[kubeconfig] Writing “admin.conf” kubeconfig file
[kubeconfig] Writing “kubelet.conf” kubeconfig file
[kubeconfig] Writing “controller-manager.conf” kubeconfig file
[kubeconfig] Writing “scheduler.conf” kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file “/var/lib/kubelet/kubeadm-flags.env”
[kubelet-start] Writing kubelet configuration to file “/var/lib/kubelet/config.yaml”
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder “/etc/kubernetes/manifests”
[control-plane] Creating static Pod manifest for “kube-apiserver”
[control-plane] Creating static Pod manifest for “kube-controller-manager”
[control-plane] Creating static Pod manifest for “kube-scheduler”
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory “/etc/kubernetes/manifests”. This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- ‘systemctl status kubelet’
- ‘journalctl -xeu kubelet’
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- ‘crictl –runtime-endpoint unix:///run/containerd/containerd.sock ps -a | grep kube | grep -v pause’
Once you have found the failing container, you can inspect its logs with:
- ‘crictl –runtime-endpoint unix:///run/containerd/containerd.sock logs CONTAINERID’
error execution phase wait-control-plane: couldn’t initialize a Kubernetes cluster
To see the stack trace of this error execute with –v=5 or higher
11:15:24 CST stdout: [sdt]
[reset] Reading configuration from the cluster…
[reset] FYI: You can look at this config file with ‘kubectl -n kube-system get cm kubeadm-config -o yaml’
W1027 11:15:24.206597 22141 reset.go:106] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get config map: Get “https://lb.kubesphere.local:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config?timeout=10s”: dial tcp 10.10.30.30:6443: connect: connection refused
[preflight] Running pre-flight checks
W1027 11:15:24.206862 22141 removeetcdmember.go:106] [reset] No kubeadm config, using etcd pod spec to get data directory
[reset] Deleted contents of the etcd data directory: /var/lib/etcd
[reset] Stopping the kubelet service
[reset] Unmounting mounted directories in “/var/lib/kubelet”
[reset] Deleting contents of directories: [/etc/kubernetes/manifests /var/lib/kubelet /etc/kubernetes/pki]
[reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf]
The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d
The reset process does not reset or clean up iptables rules or IPVS tables.
If you wish to reset iptables, you must do so manually by using the “iptables” command.
If your cluster was setup to utilize IPVS, run ipvsadm –clear (or similar)
to reset your system’s IPVS tables.
The reset process does not clean your kubeconfig files and you must remove them manually.
Please, check the contents of the $HOME/.kube/config file.
11:15:24 CST message: [sdt]
init kubernetes cluster failed: Failed to exec command: sudo -E /bin/bash -c “/usr/local/bin/kubeadm init –config=/etc/kubernetes/kubeadm-config.yaml –ignore-preflight-errors=FileExisting-crictl,ImagePull”
W1027 11:11:19.972944 21900 utils.go:69] The recommended value for “clusterDNS” in “KubeletConfiguration” is: [172.16.0.10]; the provided value is: [169.254.25.10]
[init] Using Kubernetes version: v1.27.4
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using ‘kubeadm config images pull’
W1027 11:11:20.391319 21900 checks.go:835] detected that the sandbox image “registry.k8s.io/pause:3.8” of the container runtime is inconsistent with that used by kubeadm. It is recommended that using “registry.cn-beijing.aliyuncs.com/kubesphereio/pause:3.9” as the CRI sandbox image.
[certs] Using certificateDir folder “/etc/kubernetes/pki”
[certs] Generating “ca” certificate and key
[certs] Generating “apiserver” certificate and key
[certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local lb.kubesphere.local localhost sdt sdt.cluster.local] and IPs [172.16.0.1 10.10.30.30 127.0.0.1]
[certs] Generating “apiserver-kubelet-client” certificate and key
[certs] Generating “front-proxy-ca” certificate and key
[certs] Generating “front-proxy-client” certificate and key
[certs] External etcd mode: Skipping etcd/ca certificate authority generation
[certs] External etcd mode: Skipping etcd/server certificate generation
[certs] External etcd mode: Skipping etcd/peer certificate generation
[certs] External etcd mode: Skipping etcd/healthcheck-client certificate generation
[certs] External etcd mode: Skipping apiserver-etcd-client certificate generation
[certs] Generating “sa” key and public key
[kubeconfig] Using kubeconfig folder “/etc/kubernetes”
[kubeconfig] Writing “admin.conf” kubeconfig file
[kubeconfig] Writing “kubelet.conf” kubeconfig file
[kubeconfig] Writing “controller-manager.conf” kubeconfig file
[kubeconfig] Writing “scheduler.conf” kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file “/var/lib/kubelet/kubeadm-flags.env”
[kubelet-start] Writing kubelet configuration to file “/var/lib/kubelet/config.yaml”
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder “/etc/kubernetes/manifests”
[control-plane] Creating static Pod manifest for “kube-apiserver”
[control-plane] Creating static Pod manifest for “kube-controller-manager”
[control-plane] Creating static Pod manifest for “kube-scheduler”
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory “/etc/kubernetes/manifests”. This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- ‘systemctl status kubelet’
- ‘journalctl -xeu kubelet’
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- ‘crictl –runtime-endpoint unix:///run/containerd/containerd.sock ps -a | grep kube | grep -v pause’
Once you have found the failing container, you can inspect its logs with:
- ‘crictl –runtime-endpoint unix:///run/containerd/containerd.sock logs CONTAINERID’
error execution phase wait-control-plane: couldn’t initialize a Kubernetes cluster
To see the stack trace of this error execute with –v=5 or higher: Process exited with status 1
11:15:24 CST retry: [sdt]`