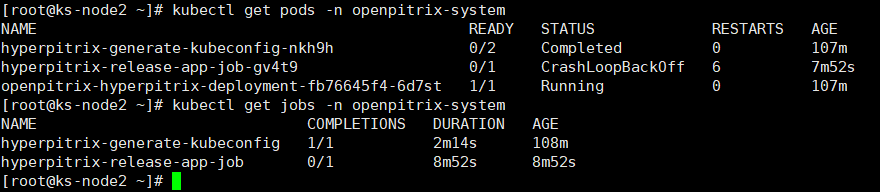
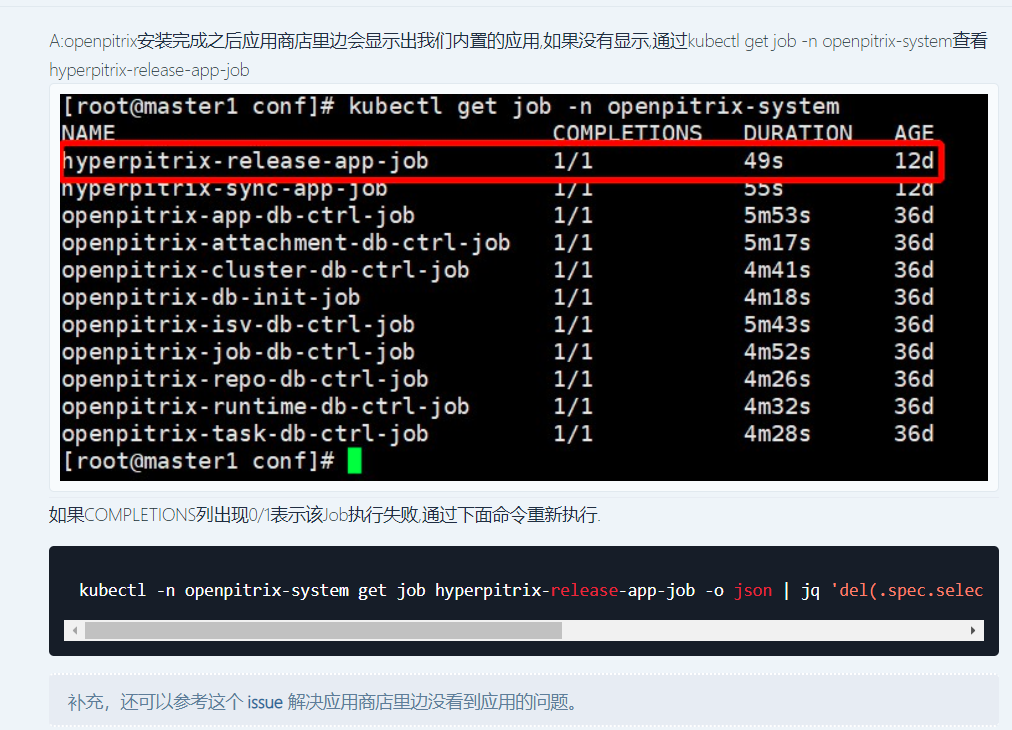
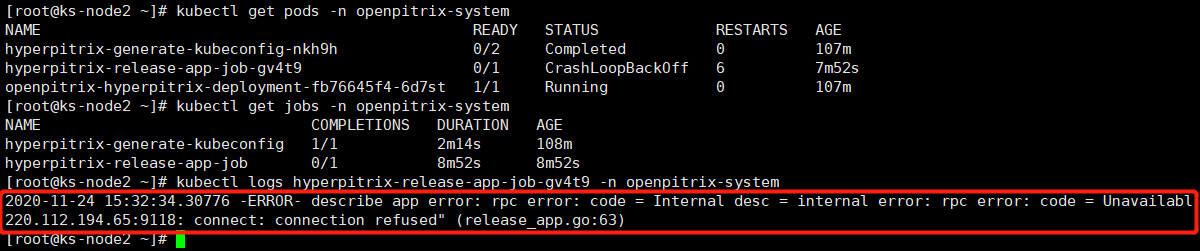
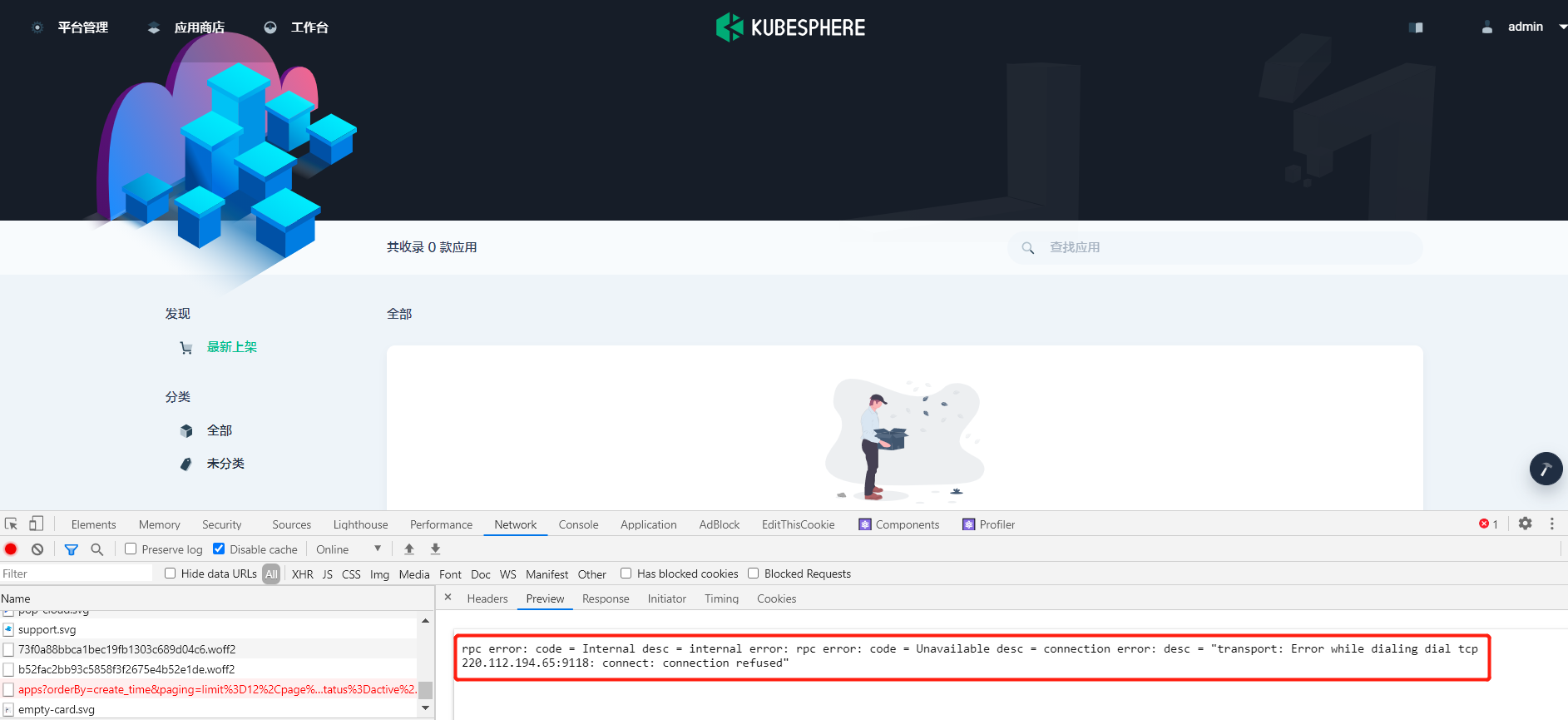
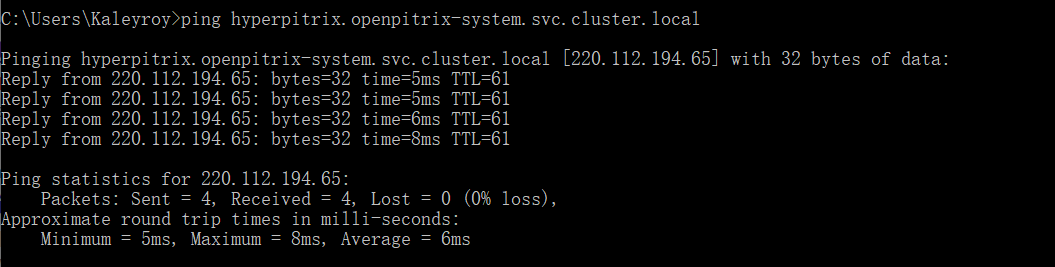
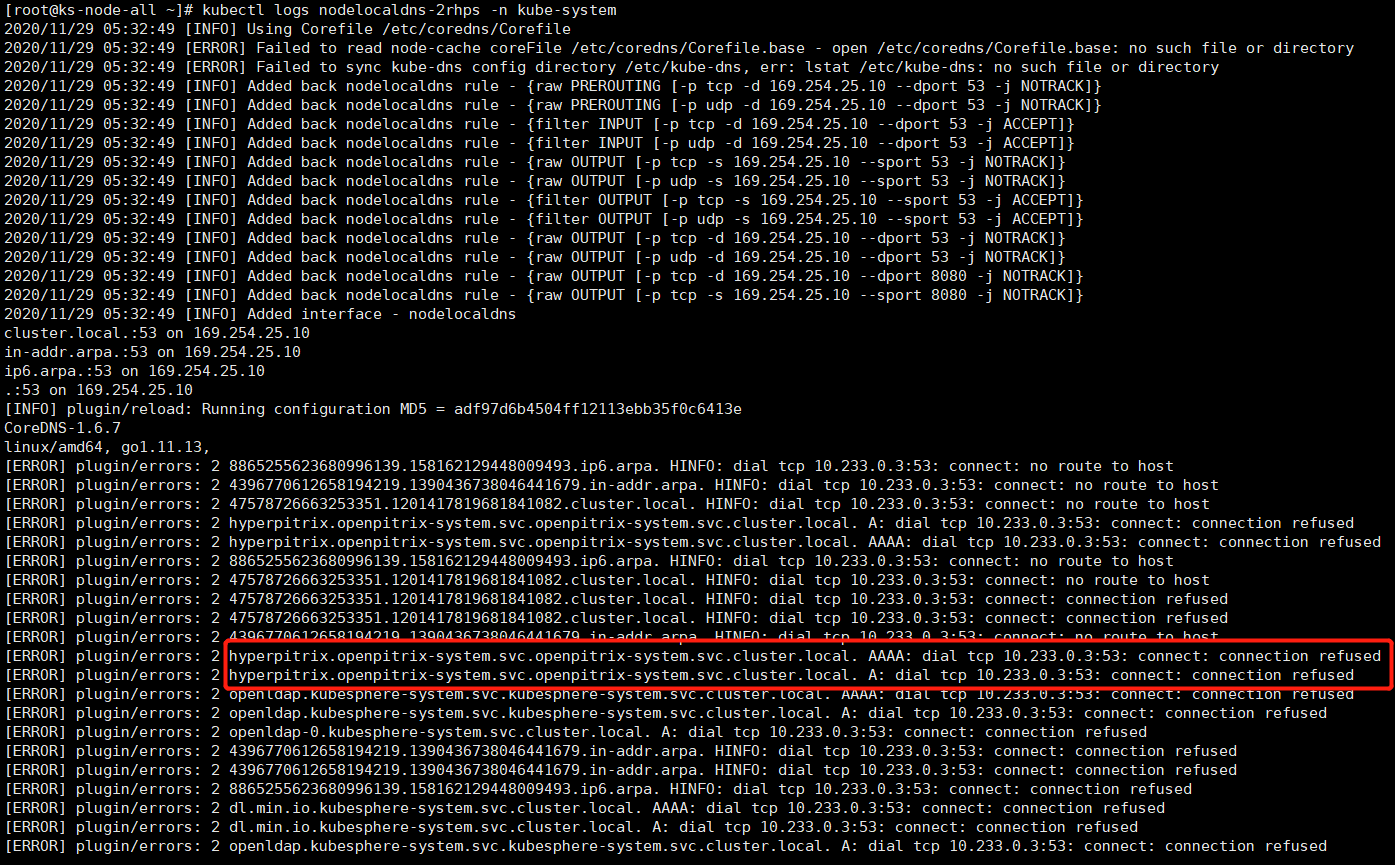
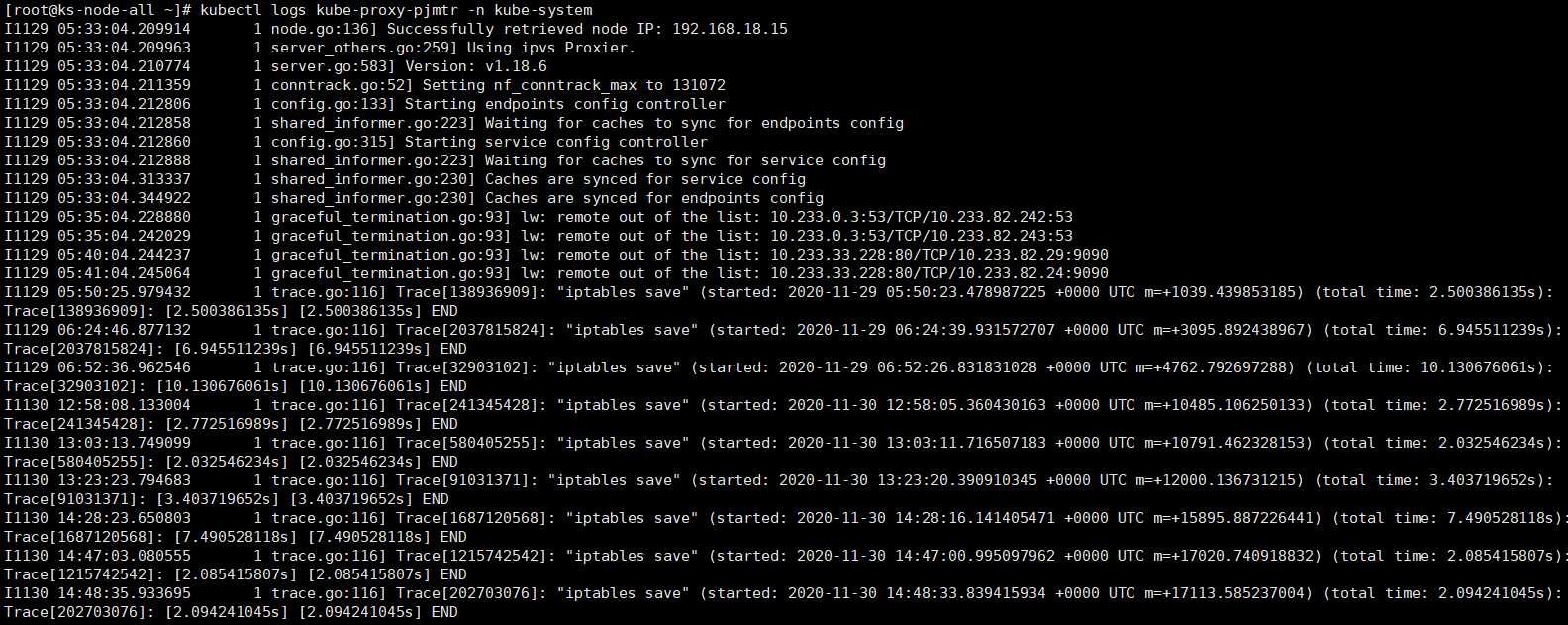
zheng1 参考各种网上的帖子,最终通过修改 nodelocaldns 的configmap配置,应用商店才是显示出来了,但是不知道这样修改对后续的DNS解析有没有影响?整体上也说不出具体的原因,也不明白为啥在我的环境中 只有在安装 openpitrix 应用商店时才会出现这个问题。
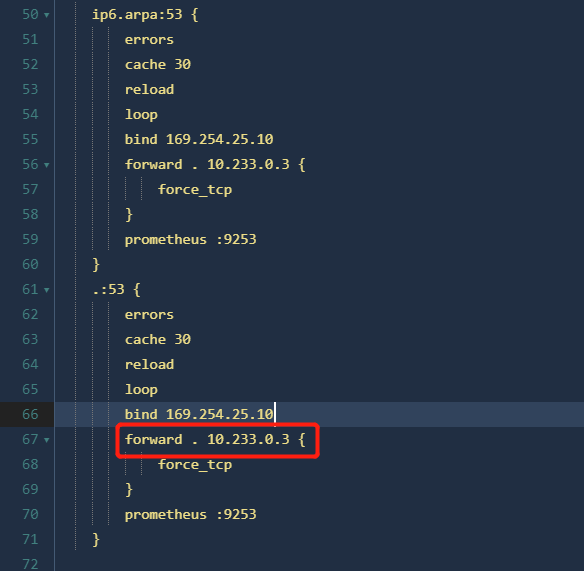
原来的 nodelocaldns 配置,解析交由本地 /etc/resolv.conf 进行,默认的 nameserver 是 114.114.114.114
.:53 {
errors
cache 30
reload
loop
bind 169.254.25.10
forward . /etc/resolv.conf
prometheus :9253
}
现在改为如下图所示,转到 CoreDNS 去解析
最后再执行 以下命令重启 hyperpitrix-release-app-job 即可
kubectl -n openpitrix-system get job hyperpitrix-release-app-job -o json | jq 'del(.spec.selector)' | jq 'del(.spec.template.metadata.labels)' | kubectl replace --force -f -