版本:ks2.1
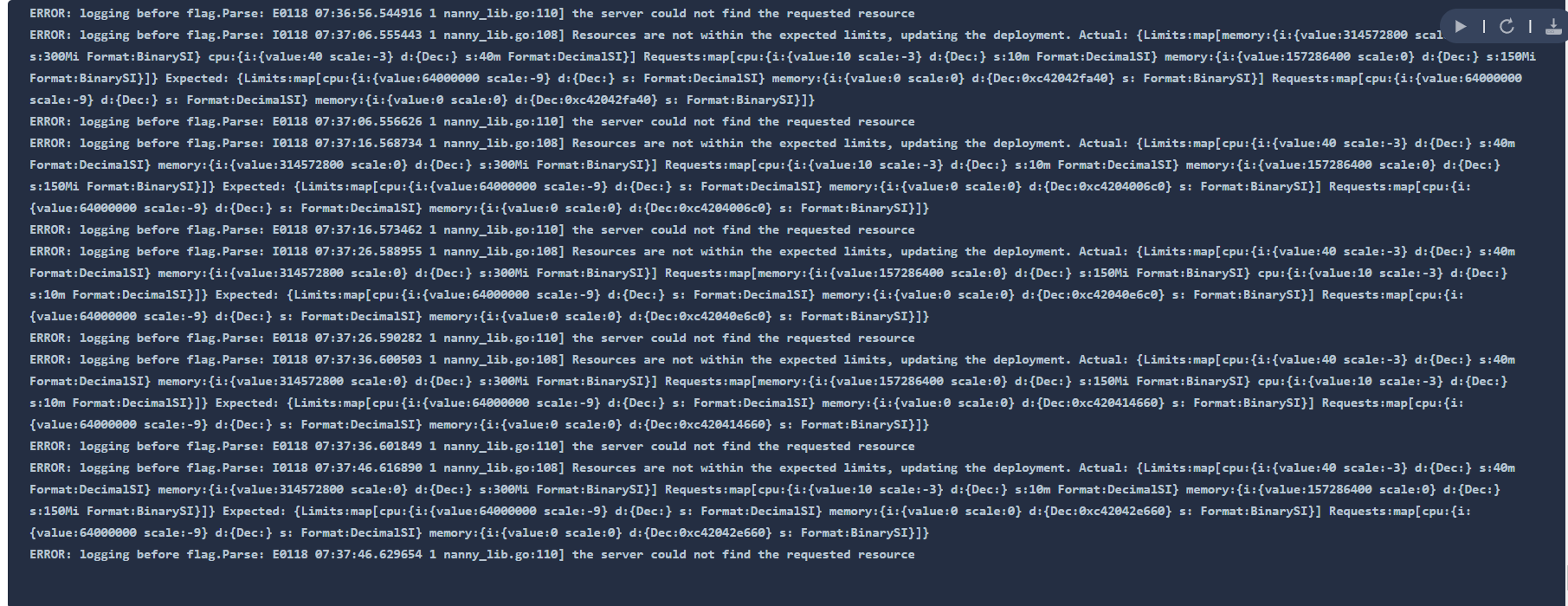
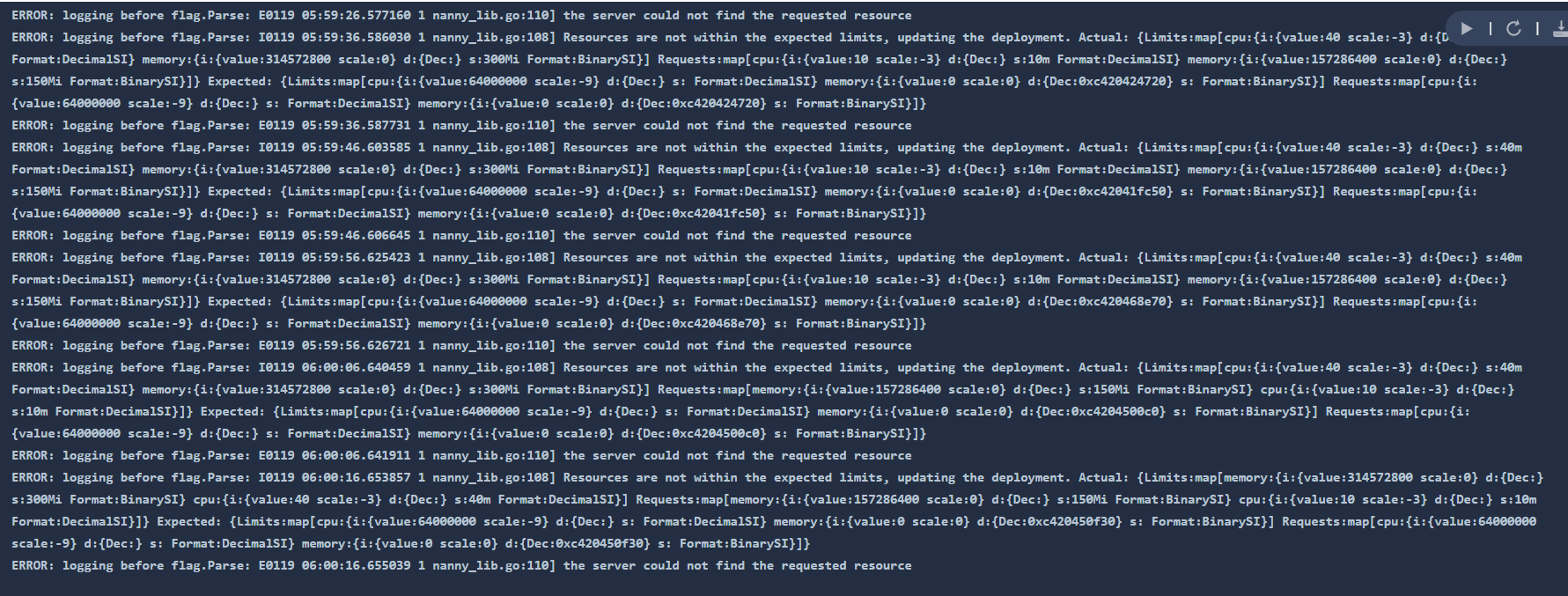
现象:ks console首页监控大屏监控基本挂掉,promethus一直在重启,而且在重启前内存占用比之前要高很多直到OOM:

日志:
level=info ts=2021-01-18T06:34:34.672258735Z caller=main.go:244 msg="Starting Prometheus" version="(version=2.5.0, branch=HEAD, revision=67dc912ac8b24f94a1fc478f352d25179c94ab9b)"
level=info ts=2021-01-18T06:34:34.672377932Z caller=main.go:245 build_context="(go=go1.11.1, user=root@578ab108d0b9, date=20181106-11:40:44)"
level=info ts=2021-01-18T06:34:34.672400543Z caller=main.go:246 host_details="(Linux 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x86_64 prometheus-k8s-1 (none))"
level=info ts=2021-01-18T06:34:34.672420668Z caller=main.go:247 fd_limits="(soft=1048576, hard=1048576)"
level=info ts=2021-01-18T06:34:34.672436666Z caller=main.go:248 vm_limits="(soft=unlimited, hard=unlimited)"
level=info ts=2021-01-18T06:34:34.673270072Z caller=main.go:562 msg="Starting TSDB ..."
level=info ts=2021-01-18T06:34:34.673382357Z caller=web.go:399 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2021-01-18T06:34:34.676263536Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610323200000 maxt=1610344800000 ulid=01EVRAS1XF3X554BG43V4AHS7P
level=info ts=2021-01-18T06:34:34.677553708Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610344800000 maxt=1610366400000 ulid=01EVRZC7M9AMQACTCCPKC0AH20
level=info ts=2021-01-18T06:34:34.678443654Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610366400000 maxt=1610388000000 ulid=01EVSKZAT15DSS8K4QQDGM4574
level=info ts=2021-01-18T06:34:34.680428634Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610388000000 maxt=1610409600000 ulid=01EVT8JEEZGGHVTP004T040QWT
level=info ts=2021-01-18T06:34:34.681686634Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610409600000 maxt=1610431200000 ulid=01EVTX5MFWCME0MBXKZSF5XXD0
level=info ts=2021-01-18T06:34:34.682847006Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610431200000 maxt=1610452800000 ulid=01EVVHRSY9VPN4G8KNBBQBS5ZR
level=info ts=2021-01-18T06:34:34.686345572Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610452800000 maxt=1610474400000 ulid=01EVW6BZT4BBF4007KPN7E271K
level=info ts=2021-01-18T06:34:34.691138631Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610474400000 maxt=1610496000000 ulid=01EVWTZ5MB326NWEY9DMREADTN
level=info ts=2021-01-18T06:34:34.694138843Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610496000000 maxt=1610517600000 ulid=01EVXFJCWCNWSF23VTX9RZM60H
level=info ts=2021-01-18T06:34:34.695043056Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610517600000 maxt=1610539200000 ulid=01EVY45QKDPRGJWDQ5J5F1SD6N
level=info ts=2021-01-18T06:34:34.695965852Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610539200000 maxt=1610560800000 ulid=01EVYRRY6XGB1F3PTZPHP7Z975
level=info ts=2021-01-18T06:34:34.701097483Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610560800000 maxt=1610582400000 ulid=01EVZDC4HXW5YVD2A34MQEH7X0
level=info ts=2021-01-18T06:34:34.70251128Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610582400000 maxt=1610604000000 ulid=01EW01Z89HWCBQZKA19663RGE1
level=info ts=2021-01-18T06:34:34.703476829Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610604000000 maxt=1610625600000 ulid=01EW0PJFK360S6QRSD7Z7313PX
level=info ts=2021-01-18T06:34:34.715337935Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610625600000 maxt=1610647200000 ulid=01EW1B5NG0Q0104WB2NZ7MPD4T
level=info ts=2021-01-18T06:34:34.717620164Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610647200000 maxt=1610668800000 ulid=01EW1ZRX3PWDMREFYS6VQ8YHHC
level=info ts=2021-01-18T06:34:34.720162939Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610668800000 maxt=1610690400000 ulid=01EW2MBZJDGKFB81Q043NV5C78
level=info ts=2021-01-18T06:34:34.723323567Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610690400000 maxt=1610712000000 ulid=01EW38Z9B51NYY6F3R84RCRQNW
level=info ts=2021-01-18T06:34:34.724202736Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610712000000 maxt=1610733600000 ulid=01EW3XJCNT7XEXHHBJX9CKTJ8T
level=info ts=2021-01-18T06:34:34.725001836Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610733600000 maxt=1610755200000 ulid=01EW4J5RFHG00VJWPW0AW1MXA3
level=info ts=2021-01-18T06:34:34.725733085Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610755200000 maxt=1610776800000 ulid=01EW56S6R5JZJBGYZ7TQ4RTXRB
level=info ts=2021-01-18T06:34:34.727193849Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610776800000 maxt=1610798400000 ulid=01EW5VD6W8JRZMAAMN0YEAVADM
level=info ts=2021-01-18T06:34:34.728469054Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610798400000 maxt=1610820000000 ulid=01EW6G3YARQ2RF3ZR07VX4DZE1
level=info ts=2021-01-18T06:34:34.729480896Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610820000000 maxt=1610841600000 ulid=01EW74M4W2PTRYHAY0H23PPGQD
level=info ts=2021-01-18T06:34:34.731566808Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610841600000 maxt=1610863200000 ulid=01EW7SE0573JJDBAHHNJHJYM1Y
level=info ts=2021-01-18T06:34:34.732755308Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610863200000 maxt=1610884800000 ulid=01EW8E152QMKKWE2E05DQPRFZ6
level=info ts=2021-01-18T06:34:34.733428408Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610884800000 maxt=1610906400000 ulid=01EW92C3TH4XWNXGPXTTEF0F9Z
level=info ts=2021-01-18T06:34:34.734064347Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610928000000 maxt=1610935200000 ulid=01EW9Q177EFHRVZ82YB3BEK2W0
level=info ts=2021-01-18T06:34:34.735731971Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610906400000 maxt=1610928000000 ulid=01EW9Q1RGCWRC87AJT2MCNH7TY
level=info ts=2021-01-18T06:34:34.736999518Z caller=repair.go:35 component=tsdb msg="found healthy block" mint=1610935200000 maxt=1610942400000 ulid=01EW9XZDK0H6WB649XNA04NYPR
level=warn ts=2021-01-18T06:35:10.91706847Z caller=head.go:407 component=tsdb msg="unknown series references" count=130
level=info ts=2021-01-18T06:35:11.078096628Z caller=main.go:572 msg="TSDB started"
level=info ts=2021-01-18T06:35:11.078220081Z caller=main.go:632 msg="Loading configuration file" filename=/etc/prometheus/config_out/prometheus.env.yaml
level=info ts=2021-01-18T06:35:11.081532468Z caller=kubernetes.go:201 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2021-01-18T06:35:11.082650829Z caller=kubernetes.go:201 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2021-01-18T06:35:11.083529392Z caller=kubernetes.go:201 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2021-01-18T06:35:11.084382737Z caller=kubernetes.go:201 component="discovery manager scrape" discovery=k8s msg="Using pod service account via in-cluster config"
level=info ts=2021-01-18T06:35:11.105328838Z caller=main.go:658 msg="Completed loading of configuration file" filename=/etc/prometheus/config_out/prometheus.env.yaml
level=info ts=2021-01-18T06:35:11.105405775Z caller=main.go:531 msg="Server is ready to receive web requests."
level=warn ts=2021-01-18T06:35:16.456460619Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:pod_abnormal:count\nexpr: (count by(namespace) (kube_pod_info{job=\"kube-state-metrics\",node!=\"\"}) - sum\n by(namespace) (kube_pod_status_phase{job=\"kube-state-metrics\",phase=\"Succeeded\"})\n - sum by(namespace) (kube_pod_status_ready{condition=\"true\",job=\"kube-state-metrics\"}\n * on(pod, namespace) kube_pod_status_phase{job=\"kube-state-metrics\",phase=\"Running\"})\n - sum by(namespace) (kube_pod_container_status_waiting_reason{job=\"kube-state-metrics\",reason=\"ContainerCreating\"}))\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:16.791040167Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:pod_abnormal:ratio\nexpr: namespace:pod_abnormal:count / (sum by(namespace) (kube_pod_status_phase{job=\"kube-state-metrics\",namespace!=\"\",phase!=\"Succeeded\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:16.791861684Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:resourcequota_used:ratio\nexpr: max by(resource, namespace) (kube_resourcequota{job=\"kube-state-metrics\",type=\"used\"})\n / min by(resource, namespace) (kube_resourcequota{job=\"kube-state-metrics\",type=\"hard\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:16.86517295Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_cpu_usage:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_cpu_usage_seconds_total{image!=\"\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:16.919013761Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_memory_usage:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (container_memory_usage_bytes{image!=\"\",job=\"kubelet\",pod!=\"\"}) * on(pod, namespace)\n group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:16.97994356Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_memory_usage_wo_cache:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (container_memory_working_set_bytes{image!=\"\",job=\"kubelet\",pod!=\"\"}) * on(pod,\n namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:17.039446931Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_net_bytes_transmitted:sum_irate\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_network_transmit_bytes_total{interface!~\"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:17.091179662Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_net_bytes_received:sum_irate\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_network_receive_bytes_total{interface!~\"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:17.100211578Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:deployment_unavailable_replicas:ratio\nexpr: label_replace(label_replace(sum by(deployment, namespace) (kube_deployment_status_replicas_unavailable{job=\"kube-state-metrics\"})\n / sum by(deployment, namespace) (kube_deployment_spec_replicas{job=\"kube-state-metrics\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"Deployment:$1\", \"deployment\", \"(.*)\"), \"owner_kind\", \"Deployment\",\n \"\", \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:17.10112857Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:daemonset_unavailable_replicas:ratio\nexpr: label_replace(label_replace(sum by(daemonset, namespace) (kube_daemonset_status_number_unavailable{job=\"kube-state-metrics\"})\n / sum by(daemonset, namespace) (kube_daemonset_status_desired_number_scheduled{job=\"kube-state-metrics\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"DaemonSet:$1\", \"daemonset\", \"(.*)\"), \"owner_kind\", \"DaemonSet\", \"\",\n \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:17.102121247Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:statefulset_unavailable_replicas:ratio\nexpr: label_replace(label_replace((1 - sum by(statefulset, namespace) (kube_statefulset_status_replicas_current{job=\"kube-state-metrics\"})\n / sum by(statefulset, namespace) (kube_statefulset_replicas{job=\"kube-state-metrics\"}))\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"StatefulSet:$1\", \"statefulset\", \"(.*)\"), \"owner_kind\", \"StatefulSet\",\n \"\", \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:23.539292364Z caller=manager.go:408 component="rule manager" group=node.rules msg="Evaluating rule failed" rule="record: node:pod_count:sum\nexpr: sum by(node) ((kube_pod_status_scheduled{condition=\"true\",job=\"kube-state-metrics\"}\n > 0) * on(namespace, pod) group_left(node) kube_pod_info{job=\"kube-state-metrics\"}\n unless on(node) (kube_node_status_condition{condition=\"Ready\",job=\"kube-state-metrics\",status=~\"unknown|false\"}\n > 0))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:26.82831779Z caller=manager.go:408 component="rule manager" group=k8s.rules msg="Evaluating rule failed" rule="record: namespace:container_cpu_usage_seconds_total:sum_rate\nexpr: sum by(namespace, label_kubesphere_io_workspace) ((container_cpu_usage_seconds_total{container!=\"\",image!=\"\",job=\"kubelet\"}\n * on(namespace) group_left(label_kubesphere_io_workspace) kube_namespace_labels{job=\"kube-state-metrics\"}\n - container_cpu_usage_seconds_total{container!=\"\",image!=\"\",job=\"kubelet\"} offset\n 90s * on(namespace) group_left(label_kubesphere_io_workspace) kube_namespace_labels{job=\"kube-state-metrics\"})\n / 90)\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:26.84646296Z caller=manager.go:408 component="rule manager" group=k8s.rules msg="Evaluating rule failed" rule="record: namespace:container_memory_usage_bytes:sum\nexpr: sum by(namespace, label_kubesphere_io_workspace) (container_memory_usage_bytes{container!=\"\",image!=\"\",job=\"kubelet\"}\n * on(namespace) group_left(label_kubesphere_io_workspace) kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:26.866354895Z caller=manager.go:408 component="rule manager" group=k8s.rules msg="Evaluating rule failed" rule="record: namespace:container_memory_usage_bytes_wo_cache:sum\nexpr: sum by(namespace, label_kubesphere_io_workspace) (container_memory_working_set_bytes{container!=\"\",image!=\"\",job=\"kubelet\"}\n * on(namespace) group_left(label_kubesphere_io_workspace) kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:45.993881968Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:pod_abnormal:count\nexpr: (count by(namespace) (kube_pod_info{job=\"kube-state-metrics\",node!=\"\"}) - sum\n by(namespace) (kube_pod_status_phase{job=\"kube-state-metrics\",phase=\"Succeeded\"})\n - sum by(namespace) (kube_pod_status_ready{condition=\"true\",job=\"kube-state-metrics\"}\n * on(pod, namespace) kube_pod_status_phase{job=\"kube-state-metrics\",phase=\"Running\"})\n - sum by(namespace) (kube_pod_container_status_waiting_reason{job=\"kube-state-metrics\",reason=\"ContainerCreating\"}))\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.092105162Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:pod_abnormal:ratio\nexpr: namespace:pod_abnormal:count / (sum by(namespace) (kube_pod_status_phase{job=\"kube-state-metrics\",namespace!=\"\",phase!=\"Succeeded\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.093067203Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:resourcequota_used:ratio\nexpr: max by(resource, namespace) (kube_resourcequota{job=\"kube-state-metrics\",type=\"used\"})\n / min by(resource, namespace) (kube_resourcequota{job=\"kube-state-metrics\",type=\"hard\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"})\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.153995588Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_cpu_usage:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_cpu_usage_seconds_total{image!=\"\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.207408597Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_memory_usage:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (container_memory_usage_bytes{image!=\"\",job=\"kubelet\",pod!=\"\"}) * on(pod, namespace)\n group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.261417089Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_memory_usage_wo_cache:sum\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (container_memory_working_set_bytes{image!=\"\",job=\"kubelet\",pod!=\"\"}) * on(pod,\n namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.309141793Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_net_bytes_transmitted:sum_irate\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_network_transmit_bytes_total{interface!~\"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.352904221Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:workload_net_bytes_received:sum_irate\nexpr: sum by(namespace, workload, owner_kind) (label_replace(label_join(sum by(namespace,\n pod) (irate(container_network_receive_bytes_total{interface!~\"^(cali.+|tunl.+|dummy.+|kube.+|flannel.+|cni.+|docker.+|veth.+|lo.*)\",job=\"kubelet\",pod!=\"\"}[5m]))\n * on(pod, namespace) group_left(owner_kind, owner_name) label_replace(label_join(label_replace(label_replace(kube_pod_owner{job=\"kube-state-metrics\"},\n \"owner_kind\", \"Deployment\", \"owner_kind\", \"ReplicaSet\"), \"owner_kind\", \"Pod\", \"owner_kind\",\n \"<none>\"), \"tmp\", \":\", \"owner_name\", \"pod\"), \"owner_name\", \"$1\", \"tmp\", \"<none>:(.*)\"),\n \"workload\", \":\", \"owner_kind\", \"owner_name\"), \"workload\", \"$1\", \"workload\", \"(Deployment:.+)-(.+)\"))\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.362537236Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:deployment_unavailable_replicas:ratio\nexpr: label_replace(label_replace(sum by(deployment, namespace) (kube_deployment_status_replicas_unavailable{job=\"kube-state-metrics\"})\n / sum by(deployment, namespace) (kube_deployment_spec_replicas{job=\"kube-state-metrics\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"Deployment:$1\", \"deployment\", \"(.*)\"), \"owner_kind\", \"Deployment\",\n \"\", \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.363552697Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:daemonset_unavailable_replicas:ratio\nexpr: label_replace(label_replace(sum by(daemonset, namespace) (kube_daemonset_status_number_unavailable{job=\"kube-state-metrics\"})\n / sum by(daemonset, namespace) (kube_daemonset_status_desired_number_scheduled{job=\"kube-state-metrics\"})\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"DaemonSet:$1\", \"daemonset\", \"(.*)\"), \"owner_kind\", \"DaemonSet\", \"\",\n \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"
level=warn ts=2021-01-18T06:35:46.364585858Z caller=manager.go:408 component="rule manager" group=namespace.rules msg="Evaluating rule failed" rule="record: namespace:statefulset_unavailable_replicas:ratio\nexpr: label_replace(label_replace((1 - sum by(statefulset, namespace) (kube_statefulset_status_replicas_current{job=\"kube-state-metrics\"})\n / sum by(statefulset, namespace) (kube_statefulset_replicas{job=\"kube-state-metrics\"}))\n * on(namespace) group_left(label_kubesphere_io_workspace) (kube_namespace_labels{job=\"kube-state-metrics\"}),\n \"workload\", \"StatefulSet:$1\", \"statefulset\", \"(.*)\"), \"owner_kind\", \"StatefulSet\",\n \"\", \"\")\n" err="many-to-many matching not allowed: matching labels must be unique on one side"