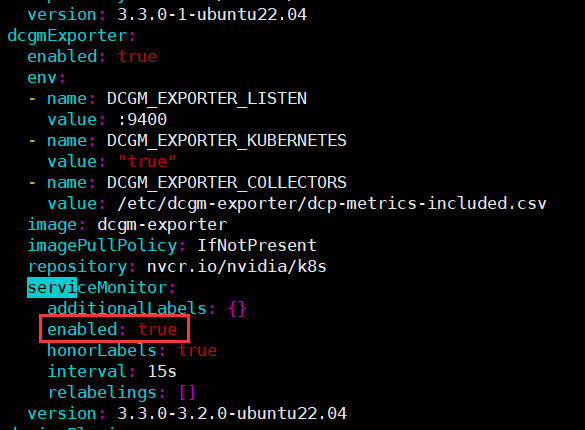
kubectl apply -f gpu-monitor.yaml 在用了这个命令对集群GPU进行监控的,为什么过一段时间后这个服务就回自动停止呢,我的yaml文件配置:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nvidia-dcgm-exporter
namespace: gpu-operator-resources
labels:
app: nvidia-dcgm-exporter
spec:
jobLabel: nvidia-gpu-resources
endpoints: