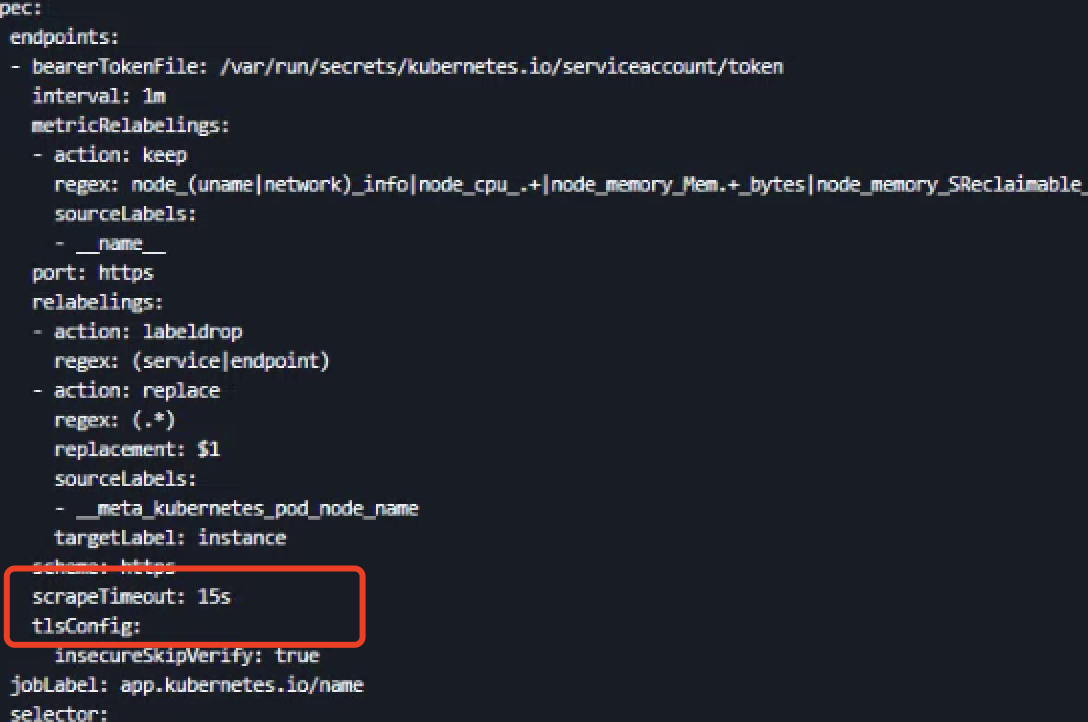
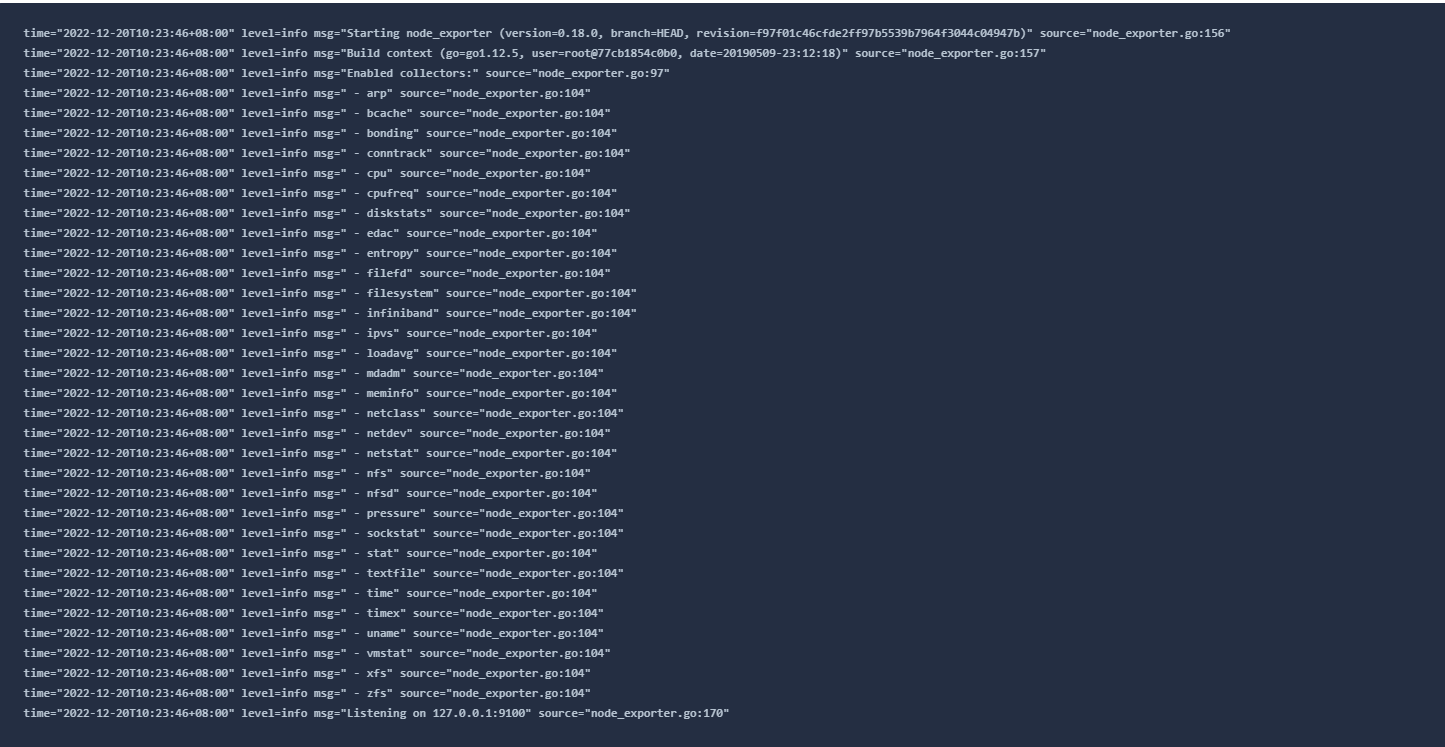
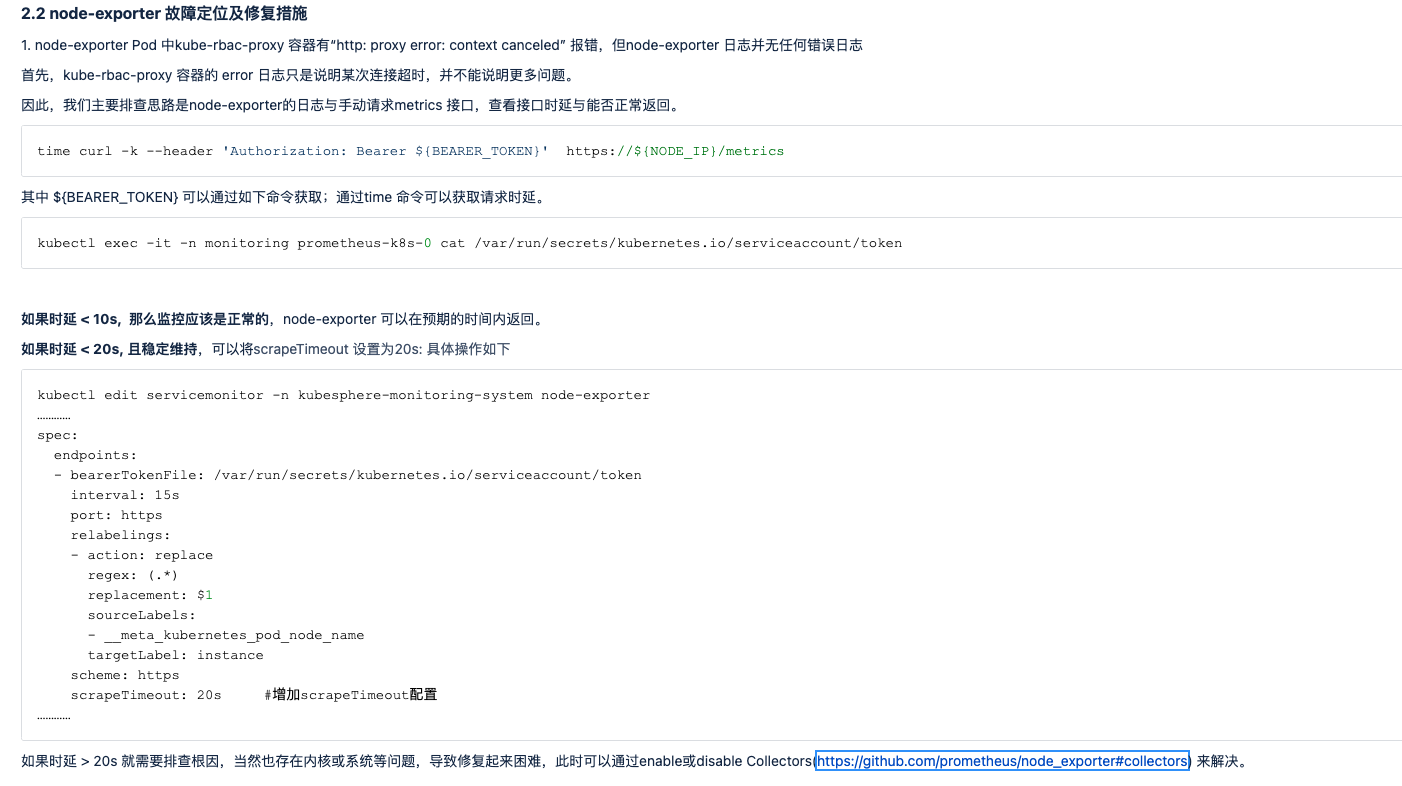
frezes frezes 然后如果耗时稍微大于 10s,可以正常返回, 可以配置下node-exporter的servicemonitor,增加scrapeTimeout: 15s 字段 kubectl edit servicemonitor -n kubesphere-monitoring-system node-exporter 如果接口不能正常返回,就要排查node-exporter的日志报错信息,解决问题或禁用部分模块以保证接口返回
frezes coke kubectl exec -it -n kubesphere-monitoring-system prometheus-k8s-0 cat /var/run/secrets/kubernetes.io/serviceaccount/token
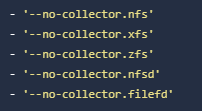
frezes frezes 我看过node-exporter有类似的issus,就只是时延过高,可能是文件系统如nfs/xfs等导致的,issue 最后也没能真正定位到问题在哪,可以去翻翻。所以这里的修复措施是disable collectors,禁用nfs/zfs/xfs,如果还有问题,考虑禁用filefd/filesystem等,这个需要尝试。 另外重启能简单恢复,但过段时间还会复现,并不能真正解决问题
frezes coke 可以增加下 –no-collector.netclass 再试试,我在其他环境中遇到了同样的问题,希望对你有效。 关联issues prometheus/node_exporter#2500