53537 看起来是 prometheus 发生过一次重启,初始化重新读取 on-disk 监控数据时发现,已有的数据 blocks 中,命为 01DRV80DEB1QP47E09CR8NRSQC 的 block 有脏数据。导致 storage 模块不能初始化而退出。prometheus-config-reloader 的报错只是正确反映了 prometheus 不可用
请问有没有对 prometheus 做什么操作( 无论是直接调 api ,还是操作 prometheus-operator)?
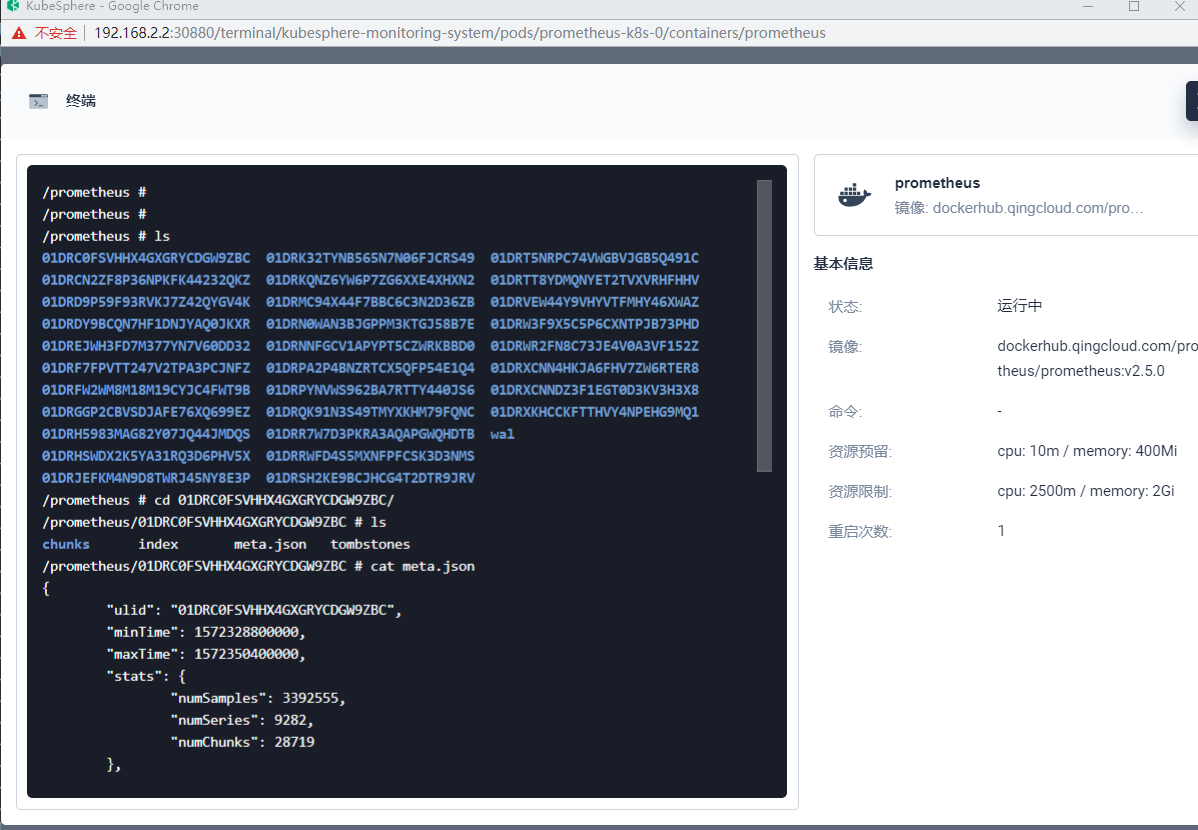
进入 prometheus 的终端看看,把 /prometheus/01DRV80DEB1QP47E09CR8NRSQC 下的文件目录结构和 meta.json 发出来看看