shaowenchen 根据前一个记录我对jenkinsfile进行了调整,在第一个stage中执行script,
jenkinsfile如下:
pipeline {
agent {
node {
label 'maven'
}
}
stages {
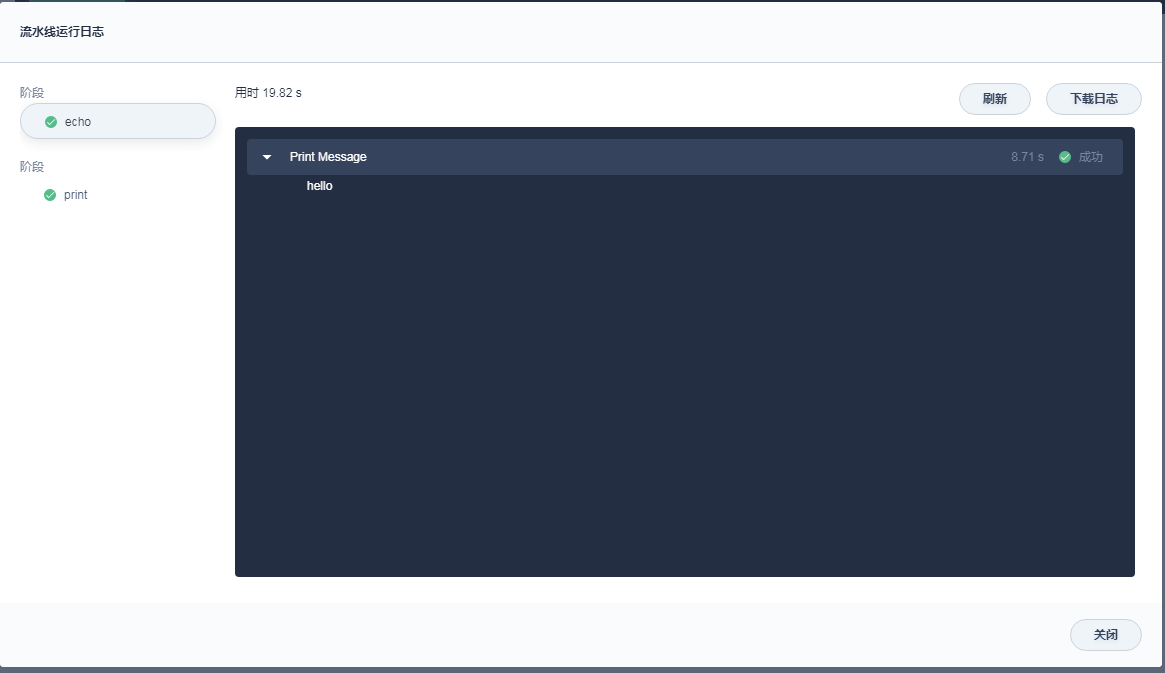
stage('echo') {
steps {
echo 'hello'
script {
print "hello"
}
}
}
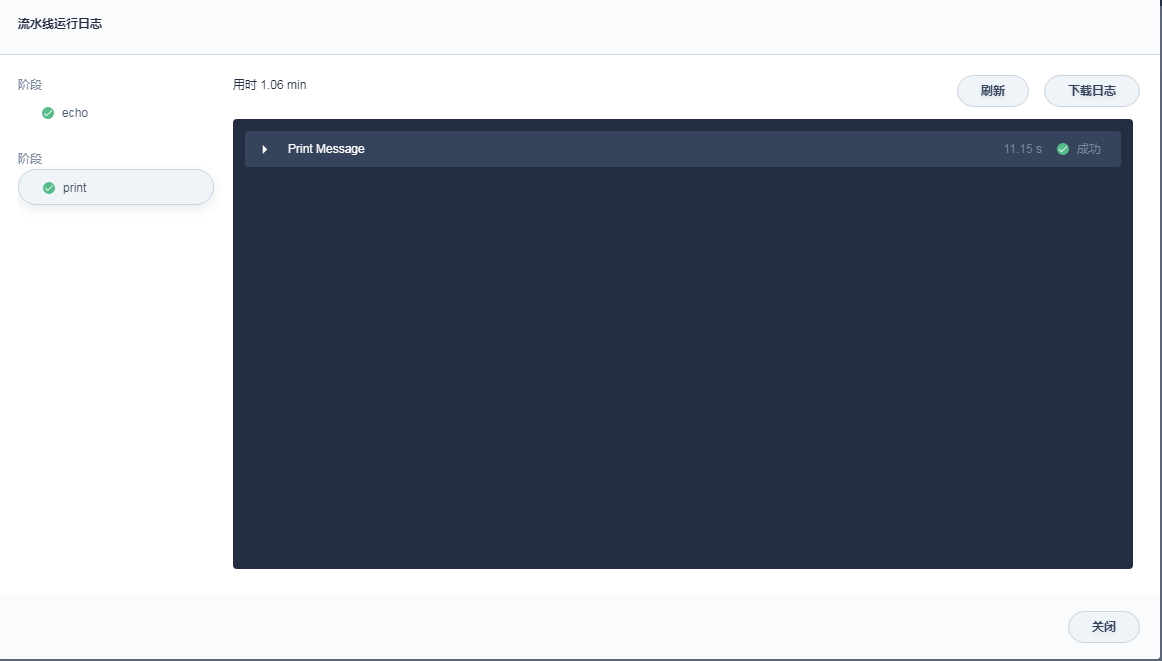
stage('print') {
steps {
script {
print "hello"
}
}
}
}
}
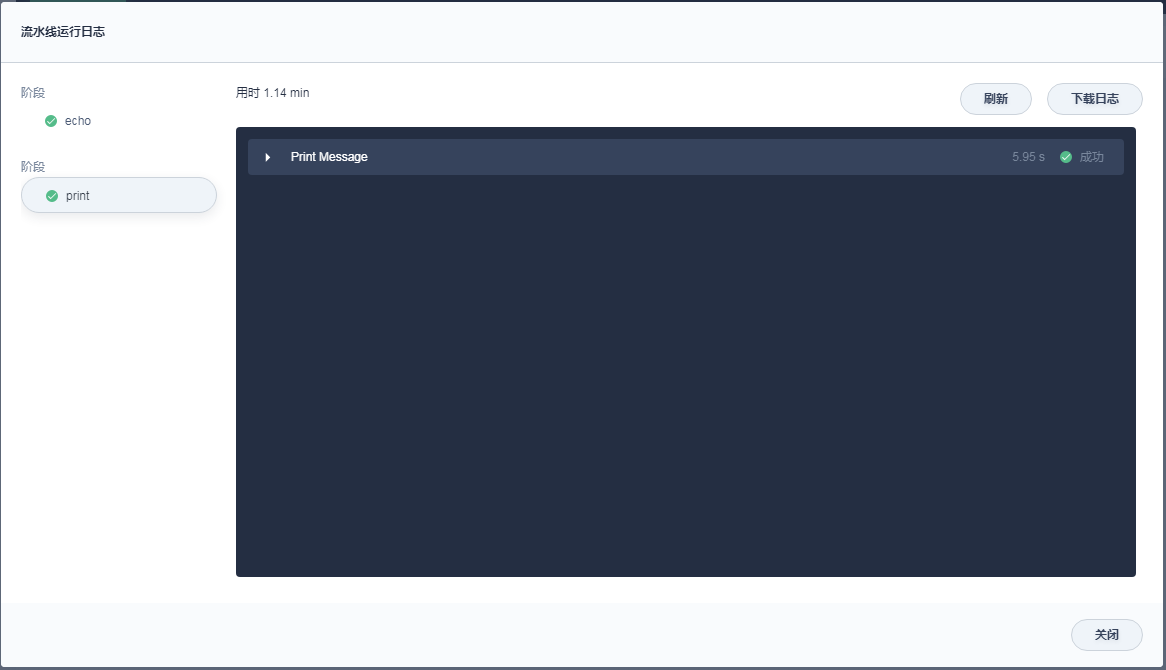
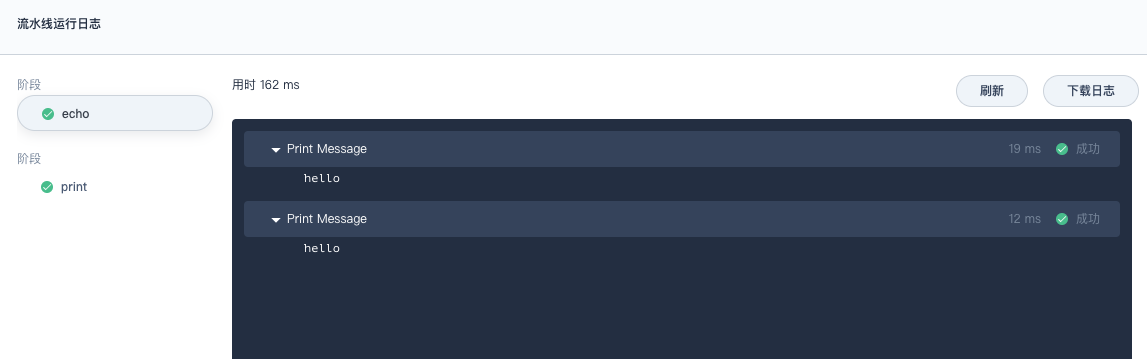
其他不变,耗时情况如下
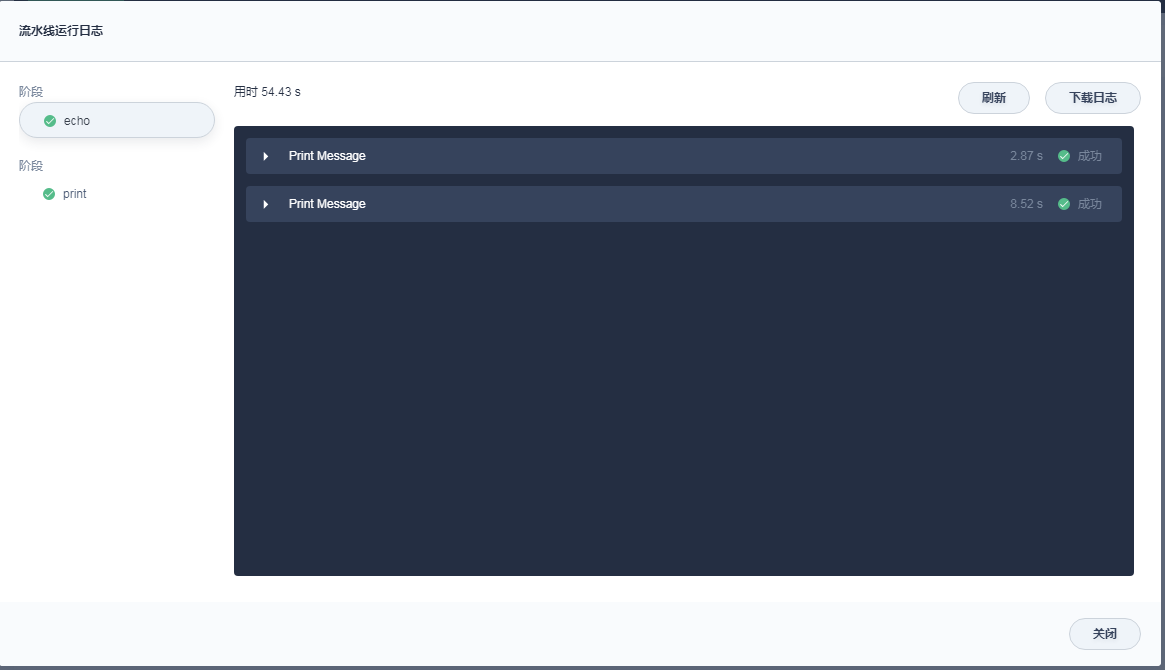
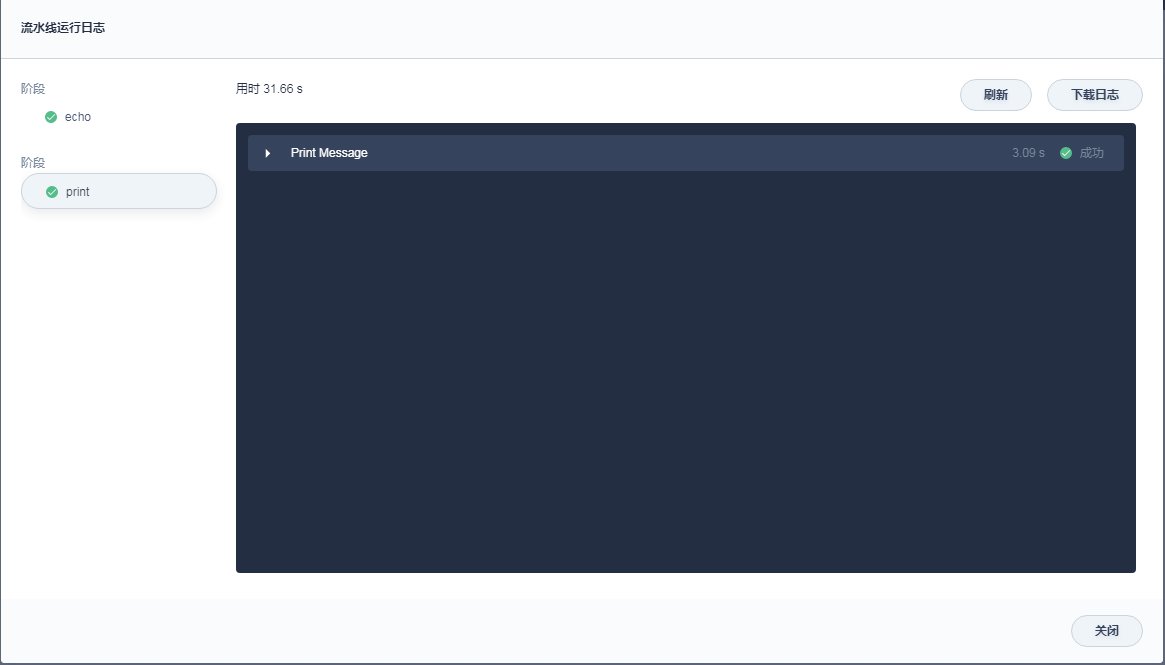
单纯的echo和print就已经达到2秒以上,感觉速度不尽人意。急需要对jenkins执行指令的速度进行加速。另外切换stage所带来的时间开销如何进行优化,毕竟写脚本的时候不希望眉毛胡子都放在一个坑位里。