补充日志:
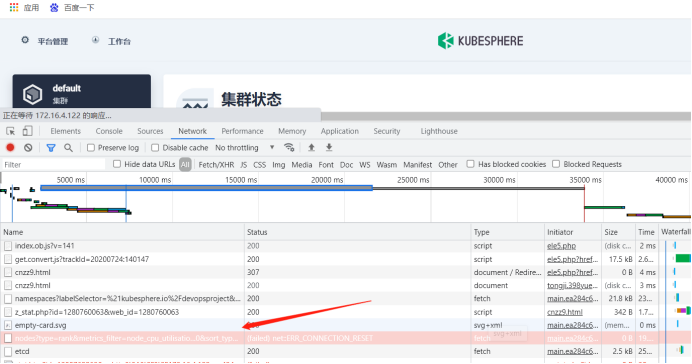
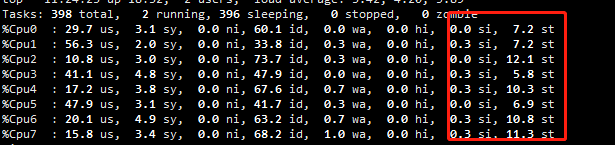
看板 资源用量–> 查看更多

104 正常环境 ks-api 日志
I0121 16:07:03.081180 1 apiserver.go:599] 10.233.70.1 - “GET /kapis/monitoring.kubesphere.io/v1alpha3/nodes?type=rank&metrics_filter=node_cpu_utilisation%7Cnode_cpu_usage%7Cnode_cpu_total%7Cnode_memory_utilisation%7Cnode_memory_usage_wo_cache%7Cnode_memory_total%7Cnode_disk_size_utilisation%7Cnode_disk_size_usage%7Cnode_disk_size_capacity%7Cnode_pod_utilisation%7Cnode_pod_running_count%7Cnode_pod_quota%7Cnode_disk_inode_utilisation%7Cnode_disk_inode_total%7Cnode_disk_inode_usage%7Cnode_load1%24&page=1&limit=10&sort_type=desc&sort_metric=node_cpu_utilisation HTTP/1.1” 200 19376 24ms
I0121 16:07:05.224580 1 apiserver.go:599] 172.26.11.105 - “GET /kapis/version HTTP/1.1” 200 539 5ms
122 异常环境 ks-api 日志
I0121 16:07:27.678941 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 15ms
I0121 16:07:29.383873 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“aff050e1-5c6a-407c-9eb6-c8a219123f27”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:27.656240Z”,“StageTimestamp”:“2022-01-21T08:07:27.679575Z”,“Annotations”:null}]}
I0121 16:07:29.415573 1 backend.go:159] send 1 auditing logs used 32
I0121 16:07:32.386193 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“fd112439-3e7d-437d-9afb-112bf1991895”,“Stage”:“ResponseComplete”,“RequestURI”:“/apis/monitoring.coreos.com/v1/namespaces/kubesphere-monitoring-system/servicemonitors/etcd”,“Verb”:“get”,“User”:{“username”:“admin”,“groups”:[“system:authenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“10.10.184.88”],“UserAgent”:“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62”,“ObjectRef”:{“Resource”:“servicemonitors”,“Namespace”:“kubesphere-monitoring-system”,“Name”:“etcd”,“UID”:"",“APIGroup”:“monitoring.coreos.com”,“APIVersion”:“v1”,“ResourceVersion”:“Namespace”,“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:31.381860Z”,“StageTimestamp”:“2022-01-21T08:07:31.401859Z”,“Annotations”:null}]}
I0121 16:07:32.424022 1 backend.go:159] send 1 auditing logs used 38
I0121 16:07:37.658649 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 3ms
I0121 16:07:38.387696 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“04b9a182-ae0a-414f-a0ab-3ff250df76b9”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:37.654466Z”,“StageTimestamp”:“2022-01-21T08:07:37.658855Z”,“Annotations”:null}]}
I0121 16:07:38.404521 1 backend.go:159] send 1 auditing logs used 17
大量日志显示
I0121 16:10:57.669299 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 11ms
I0121 16:10:59.460126 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“1cd4ae08-fd87-41fb-b933-4bda5946f466”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:10:57.656791Z”,“StageTimestamp”:“2022-01-21T08:10:57.669835Z”,“Annotations”:null}]}
I0121 16:10:59.478277 1 backend.go:159] send 1 auditing logs used 18
ks-api 日志级别已经调整为-v=9
该情况应该怎样处理呢,是在部署的时候某个sa 的权限不正确吗