
已有k8s集群上,在线安装kubesphere: v3.2.1
看下ks-installer日志安装cheng功了么?
看板页面系统监控指标为空
ks-apiserver会接受前端请求来转发给相应地子模块server,可以检查下监控系统是否正常。
已有k8s集群上,在线安装kubesphere: v3.2.1
看下ks-installer日志安装cheng功了么?
看板页面系统监控指标为空
ks-apiserver会接受前端请求来转发给相应地子模块server,可以检查下监控系统是否正常。
zhu733756
您的建议很好,我通过prometheus ui看到以下两个异常
1.以下两组异常,麻烦分析这两个 指标是由那个服务控制的呀
kubesphere-monitoring-system/kube-controller-manager/0 (↉ up)
kubesphere-monitoring-system/kube-scheduler/0 (↉ up)
kubectl logs -n kubesphere-monitoring-system node-exporter-4fvcx -c kube-rbac-proxy
I0113 05:40:30.114240 32619 main.go:190] Valid token audiences:
I0113 05:40:30.114683 32619 main.go:262] Generating self signed cert as no cert is provided
I0113 05:40:31.109490 32619 main.go:311] Starting TCP socket on [172.16.4.122]:9100
I0113 05:40:31.111076 32619 main.go:318] Listening securely on [172.16.4.122]:9100
E0115 22:13:45.516125 32619 webhook.go:111] Failed to make webhook authenticator request: Post https://10.20.0.1:443/apis/authentication.k8s.io/v1/tokenreviews: write tcp 10.20.0.1:53220->10.20.0.1:443: write: broken pipe
E0115 22:13:45.519816 32619 proxy.go:73] Unable to authenticate the request due to an error: Post https://10.20.0.1:443/apis/authentication.k8s.io/v1/tokenreviews: write tcp 10.20.0.1:53220->10.20.0.1:443: write: broken pipe关于这两个问题,您有更好的建议吗,部署方式是k8s 集群部署后,部署的kubesphere 3.2.1
关于部署有更好的建议吗
zhu733756
又来麻烦您了,我的问题仍然存在,但是现在没有找到解决问题的方向
以下是关于问题的情况

1.集群节点状态正常
2.组件状态正常
3.API Server监控正常
4.调度器监控正常
1.集群资源用例 等待好久显示 0
2.etcd监控,状态空
3.物理资源监控:转圈后显示为发现监控数据
4.资源用量排行 显示暂无数据

资源消费统计:整体显示正常
工具箱中显示指标正常,但是在看板中无法显示
<– GET /clusters/default/monitor-cluster/resource 2022/01/20T14:36:18.175
–> GET /clusters/default/monitor-cluster/resource 200 201ms 16.47kb 2022/01/20T14:36:18.374
<– GET /kapis/iam.kubesphere.io/v1alpha2/clustermembers/admin/clusterroles 2022/01/20T14:36:23.535
<– GET /kapis/resources.kubesphere.io/v1alpha3/namespaces?labelSelector=%21kubesphere.io%2Fdevopsproject&sortBy=createTime&limit=10 2022/01/20T14:36:23.965
<– GET /apis/monitoring.coreos.com/v1/namespaces/kubesphere-monitoring-system/servicemonitors/etcd 2022/01/20T14:36:24.543
以下请求没有到后端,console中无请求日志,是没有请求成功吗?
http://{ip}:30880/kapis/monitoring.kubesphere.io/v1alpha3/cluster?start=1642654597&end=1642660597&step=120s×=50&metrics_filter=cluster_cpu_utilisation|cluster_memory_utilisation|cluster_load1|cluster_load5|cluster_load15|cluster_disk_size_usage|cluster_disk_inode_utilisation|cluster_disk_inode_usage|cluster_disk_inode_total|cluster_disk_read_iops|cluster_disk_write_iops|cluster_disk_read_throughput|cluster_disk_write_throughput|cluster_net_bytes_transmitted|cluster_net_bytes_received|cluster_pod_running_count|cluster_pod_abnormal_count|cluster_pod_succeeded_count$
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:07.702
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:10.067
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:12.488
<– GET /kapis/tenant.kubesphere.io/v1alpha2/metering/price 2022/01/20T14:27:13.317
<– GET /kapis/metering.kubesphere.io/v1alpha1/cluster?start=1642003200&end=1642608000&step=3600s&metrics_filter=meter_cluster_cpu_usage%7Cmeter_cluster_memory_usage%7Cmeter_cluster_net_bytes_transmitted%7Cmeter_cluster_net_bytes_received%7Cmeter_cluster_pvc_bytes_total&resources_filter=default 2022/01/20T14:27:13.747
<– GET /kapis/metering.kubesphere.io/v1alpha1/cluster?start=1642003200&end=1642660047&step=3600s&metrics_filter=meter_cluster_cpu_usage%7Cmeter_cluster_memory_usage%7Cmeter_cluster_net_bytes_transmitted%7Cmeter_cluster_net_bytes_received%7Cmeter_cluster_pvc_bytes_total&resources_filter=default 2022/01/20T14:27:15.162
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:15.210
<– GET /kapis/resources.kubesphere.io/v1alpha3/nodes?limit=-1&page=1&sortBy=createTime&labelSelector=%21node-role.kubernetes.io%2Fedge 2022/01/20T14:27:16.202
<– GET /kapis/metering.kubesphere.io/v1alpha1/nodes?metrics_filter=meter_node_cpu_usage&resources_filter=node-02%7Cnode-01%7Cmaster-02%7Cmaster-03%7Cmaster-01 2022/01/20T14:27:16.875
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:18.234
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:20.949
<– GET /kapis/resources.kubesphere.io/v1alpha2/componenthealth 2022/01/20T14:27:24.423
Prometheus 中targer 都已经正常,并且查询指标有相关指标。
1.这些请求走ks-api 了吗,为什么每次请求 api 日志都没有刷新,是默认把 api 的日志关闭了一部分
2.指标计算的时候 不是通过 Prometheus 计算的吗,在Prometheus 中没有日志呢
1.kk 部署没有 redis
2.kk 存储使用 openebs , 我在 kubesphere on k8s 时使用的是nfs
问题会出现在这里吗
麻烦您在给看下上面的问题,最近几天一直在学习 kubesphere , 想着解决问题,顺便熟悉kubesphere 
补充日志:
看板 资源用量–> 查看更多

104 正常环境 ks-api 日志
I0121 16:07:03.081180 1 apiserver.go:599] 10.233.70.1 - “GET /kapis/monitoring.kubesphere.io/v1alpha3/nodes?type=rank&metrics_filter=node_cpu_utilisation%7Cnode_cpu_usage%7Cnode_cpu_total%7Cnode_memory_utilisation%7Cnode_memory_usage_wo_cache%7Cnode_memory_total%7Cnode_disk_size_utilisation%7Cnode_disk_size_usage%7Cnode_disk_size_capacity%7Cnode_pod_utilisation%7Cnode_pod_running_count%7Cnode_pod_quota%7Cnode_disk_inode_utilisation%7Cnode_disk_inode_total%7Cnode_disk_inode_usage%7Cnode_load1%24&page=1&limit=10&sort_type=desc&sort_metric=node_cpu_utilisation HTTP/1.1” 200 19376 24ms
I0121 16:07:05.224580 1 apiserver.go:599] 172.26.11.105 - “GET /kapis/version HTTP/1.1” 200 539 5ms
122 异常环境 ks-api 日志
I0121 16:07:27.678941 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 15ms
I0121 16:07:29.383873 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“aff050e1-5c6a-407c-9eb6-c8a219123f27”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:27.656240Z”,“StageTimestamp”:“2022-01-21T08:07:27.679575Z”,“Annotations”:null}]}
I0121 16:07:29.415573 1 backend.go:159] send 1 auditing logs used 32
I0121 16:07:32.386193 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“fd112439-3e7d-437d-9afb-112bf1991895”,“Stage”:“ResponseComplete”,“RequestURI”:“/apis/monitoring.coreos.com/v1/namespaces/kubesphere-monitoring-system/servicemonitors/etcd”,“Verb”:“get”,“User”:{“username”:“admin”,“groups”:[“system:authenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“10.10.184.88”],“UserAgent”:“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36 Edg/97.0.1072.62”,“ObjectRef”:{“Resource”:“servicemonitors”,“Namespace”:“kubesphere-monitoring-system”,“Name”:“etcd”,“UID”:"",“APIGroup”:“monitoring.coreos.com”,“APIVersion”:“v1”,“ResourceVersion”:“Namespace”,“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:31.381860Z”,“StageTimestamp”:“2022-01-21T08:07:31.401859Z”,“Annotations”:null}]}
I0121 16:07:32.424022 1 backend.go:159] send 1 auditing logs used 38
I0121 16:07:37.658649 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 3ms
I0121 16:07:38.387696 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“04b9a182-ae0a-414f-a0ab-3ff250df76b9”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:07:37.654466Z”,“StageTimestamp”:“2022-01-21T08:07:37.658855Z”,“Annotations”:null}]}
I0121 16:07:38.404521 1 backend.go:159] send 1 auditing logs used 17
大量日志显示
I0121 16:10:57.669299 1 apiserver.go:599] 172.16.4.122 - “GET /kapis/version HTTP/1.1” 200 539 11ms
I0121 16:10:59.460126 1 backend.go:168] {“Items”:[{“Devops”:"",“Workspace”:"",“Cluster”:"",“Message”:"",“Level”:“Metadata”,“AuditID”:“1cd4ae08-fd87-41fb-b933-4bda5946f466”,“Stage”:“ResponseComplete”,“RequestURI”:“/kapis/version”,“Verb”:“GET”,“User”:{“username”:“system:anonymous”,“groups”:[“system:unauthenticated”]},“ImpersonatedUser”:null,“SourceIPs”:[“172.16.4.122”],“UserAgent”:“kube-probe/1.21”,“ObjectRef”:{“Resource”:"",“Namespace”:"",“Name”:"",“UID”:"",“APIGroup”:"",“APIVersion”:"",“ResourceVersion”:"",“Subresource”:""},“ResponseStatus”:{“metadata”:{},“code”:200},“RequestObject”:null,“ResponseObject”:null,“RequestReceivedTimestamp”:“2022-01-21T08:10:57.656791Z”,“StageTimestamp”:“2022-01-21T08:10:57.669835Z”,“Annotations”:null}]}
I0121 16:10:59.478277 1 backend.go:159] send 1 auditing logs used 18
ks-api 日志级别已经调整为-v=9
该情况应该怎样处理呢,是在部署的时候某个sa 的权限不正确吗
1.集群资源用例 等待好久显示 0
采集的数据有么?有可能还是网络问题额
2.etcd监控,状态空
这个监控需要自己开启的,ks-installer可配置
3.物理资源监控:转圈后显示为发现监控数据
数据链路是client -》 ks-apiserver -> prometheus client -> prometheus query -> prometheus db
4.资源用量排行 显示暂无数据
监控指标存在么,如果查询Prometheus监控指标存在,console不存在,可以尝试重启下ks-apiserver
1.集群资源用例 等待好久显示 0
采集的数据有么?有可能还是网络问题额
Prometheus中是有数据的,我还特意找了个grafana 看板,
1)13352 kubesphere的看板上看都是正常的
2)8919 node-exporter 的看板,显示也是正常的
2.etcd监控,状态空
这个监控需要自己开启的,ks-installer可配置,这个是etcd 已经配置了,但是有部分数据不显示也不完全为空
3.物理资源监控:转圈后显示为发现监控数据
数据链路是client -》 ks-apiserver -> prometheus client -> prometheus query -> prometheus db
好的,之前请求的时候我看过 prometheus 日志,显示没有刷新,这快我继续在看下,确认下 ks-apiserver 的请求有没有到 prometheus
4.资源用量排行 显示暂无数据
监控指标存在么,如果查询Prometheus监控指标存在,console不存在,可以尝试重启下ks-apiserver
这个 ks-apiserver 重启过,我由铲除掉又重新安装了一遍还是不行,
麻烦问下,k8s集群有用kubeadm 部署后在安装 kubesphere 的吗,我在微信群里面为问了下,都是使用kk安装的,您的建议是我用kk还是 继续尝试解决这个问题呢,
期待继续交流,如您有kubeadm 安装k8s 集群的注意点可以告诉我下我继续尝试下,这块对新版是不是还没有适配过呢?
补充个看板监控信息:

这个问题困扰了很久,问题根因应该是系统本身的一些参数被更改导致的。
对比正常环境,尝试过以下几点:
开始用kubeadm安装k8s集群后部署kubesphere的,放弃kubeadm后使用kk安装依然有问题(选择的是卸载,并没有重置系统)。
最终放弃了,选择了一个worker节点用kk 部署单点,完美规避该问题。
总结,该问题可能是kubeadm 安装k8s集群引入的一个系统参数问题,具体问题没有定位到,建议遇到该问题的小伙伴,直接重新安装系统,使用kk 安装就可以了,如果麻烦,可以选择worker节点进行测试安装。
该问题困扰了小半个多月,终于有了头绪,感谢社区大佬的支持!
可能正如大佬所说该问题应该是网络问题,但是遗憾的是没有定位到具体的问题根因,具体是那个系统参数影响的。
后续我还会测试用kubeadm安装k8s集群,在安装kubesphere!
20220128 更新
master 三个节点系统重置后,问题依然存在,决定找运维部门大佬帮忙重新建三台机器进行测试下,并且确认该三台虚机支原体位置改变,具体不太清楚了,如 不在原来的物理机上更改到其他物理机或机型。
测试后结果后续补充
迁移前:
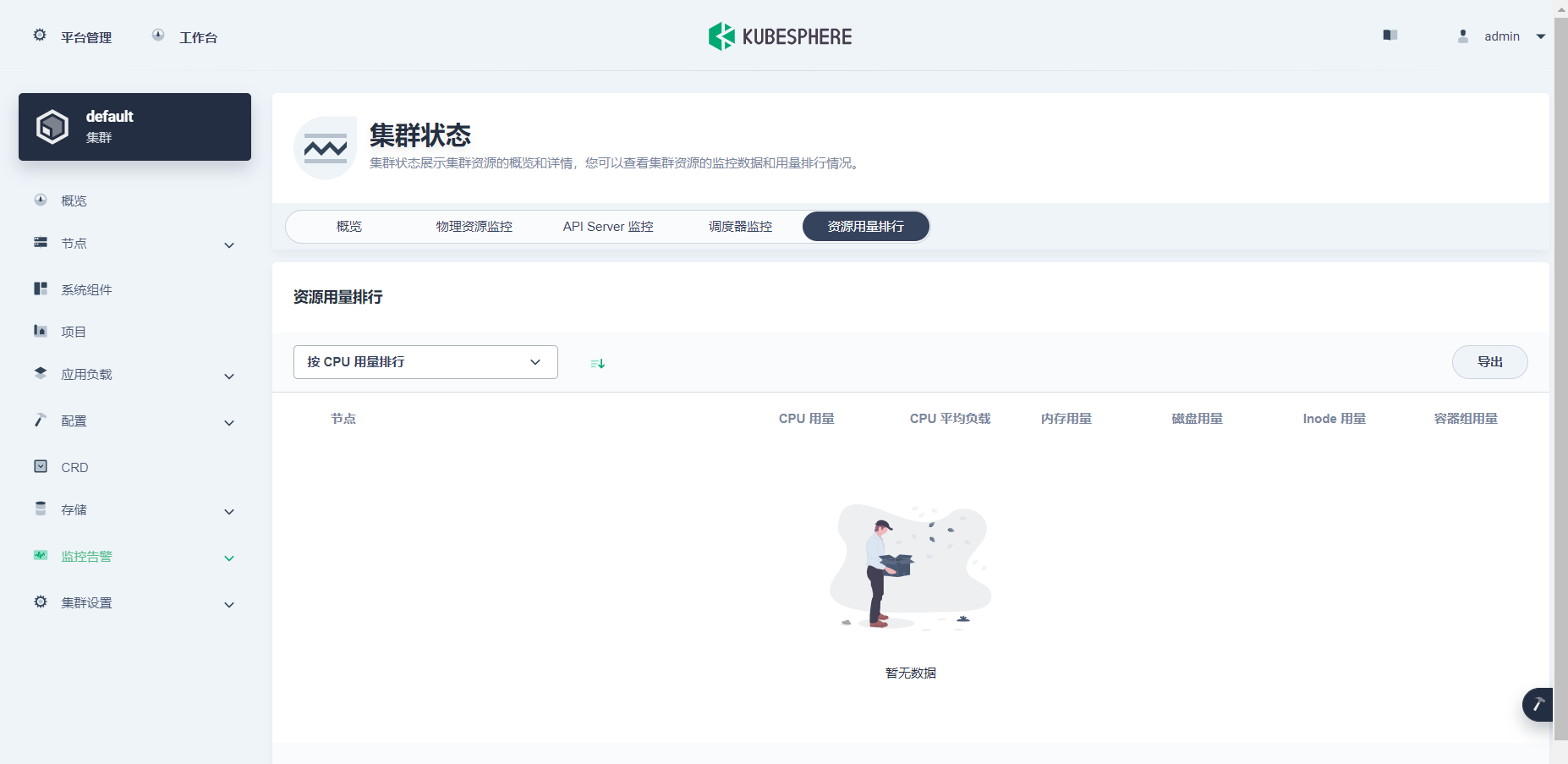
迁移后

问题原因:
底层物理机cpu资源不足,迁移后正常。 万万没想到。
top 关注st si 指标
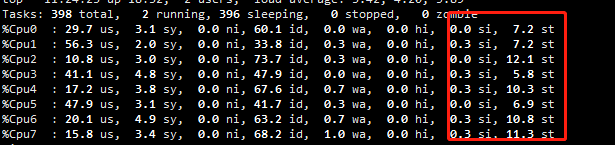
我也遇到了相同的问题,几乎和您的一模一样,也是找不到具体原因  ,我也准备重装系统了
,我也准备重装系统了
