24sama
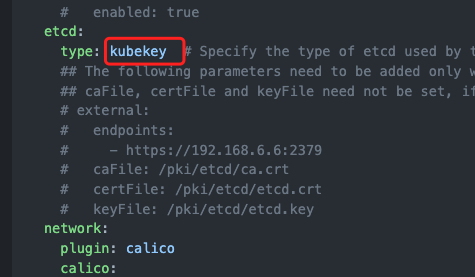
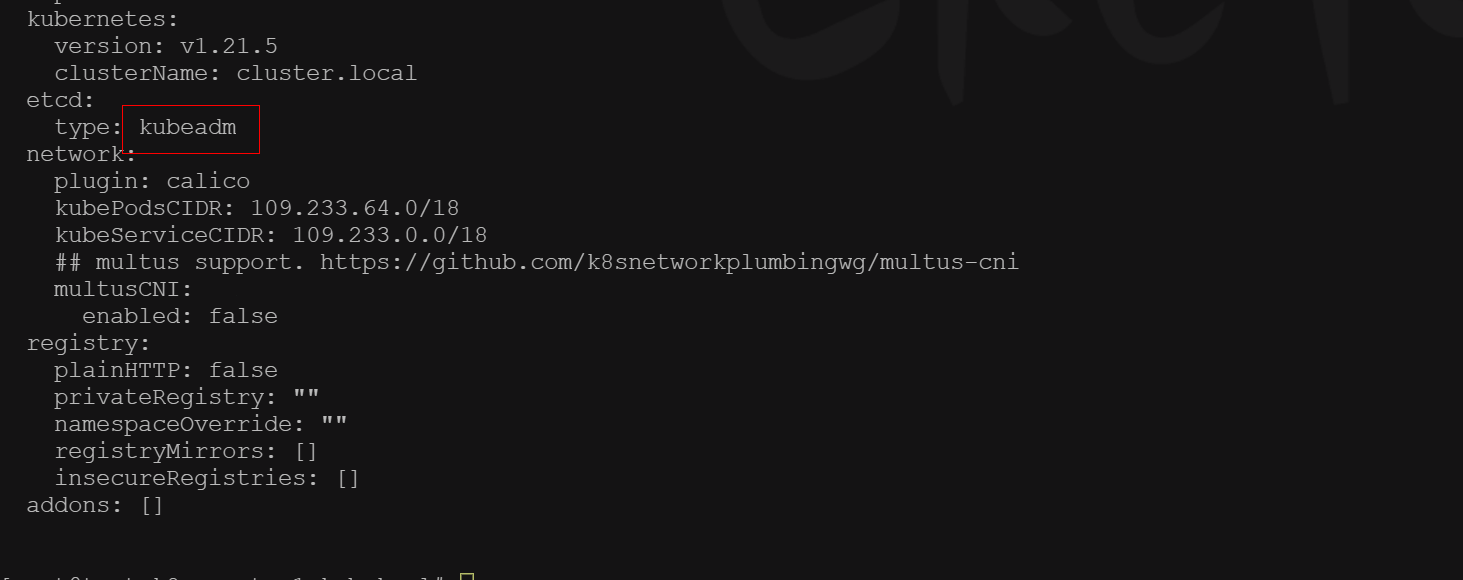
使用的kubekey是2.0.0版本的。我这边尝试了将etcd type 改为kubeadm 后依然报同样的错误。
具体错误:
etcd health check failed: Failed to exec command: sudo -E /bin/bash -c “export ETCDCTL_API=2;export ETCDCTL_CERT_FILE=‘/etc/ssl/etcd/ssl/admin-test-k8s-master3.pem’;export ETCDCTL_KEY_FILE=‘/etc/ssl/etcd/ssl/admin-test-k8s-master3-key.pem’;export ETCDCTL_CA_FILE=‘/etc/ssl/etcd/ssl/ca.pem’;/usr/local/bin/etcdctl –endpoints=https://ip:2379,https://ip:2379,https://ip:2379 cluster-health | grep -q ‘cluster is healthy’”