hyt05
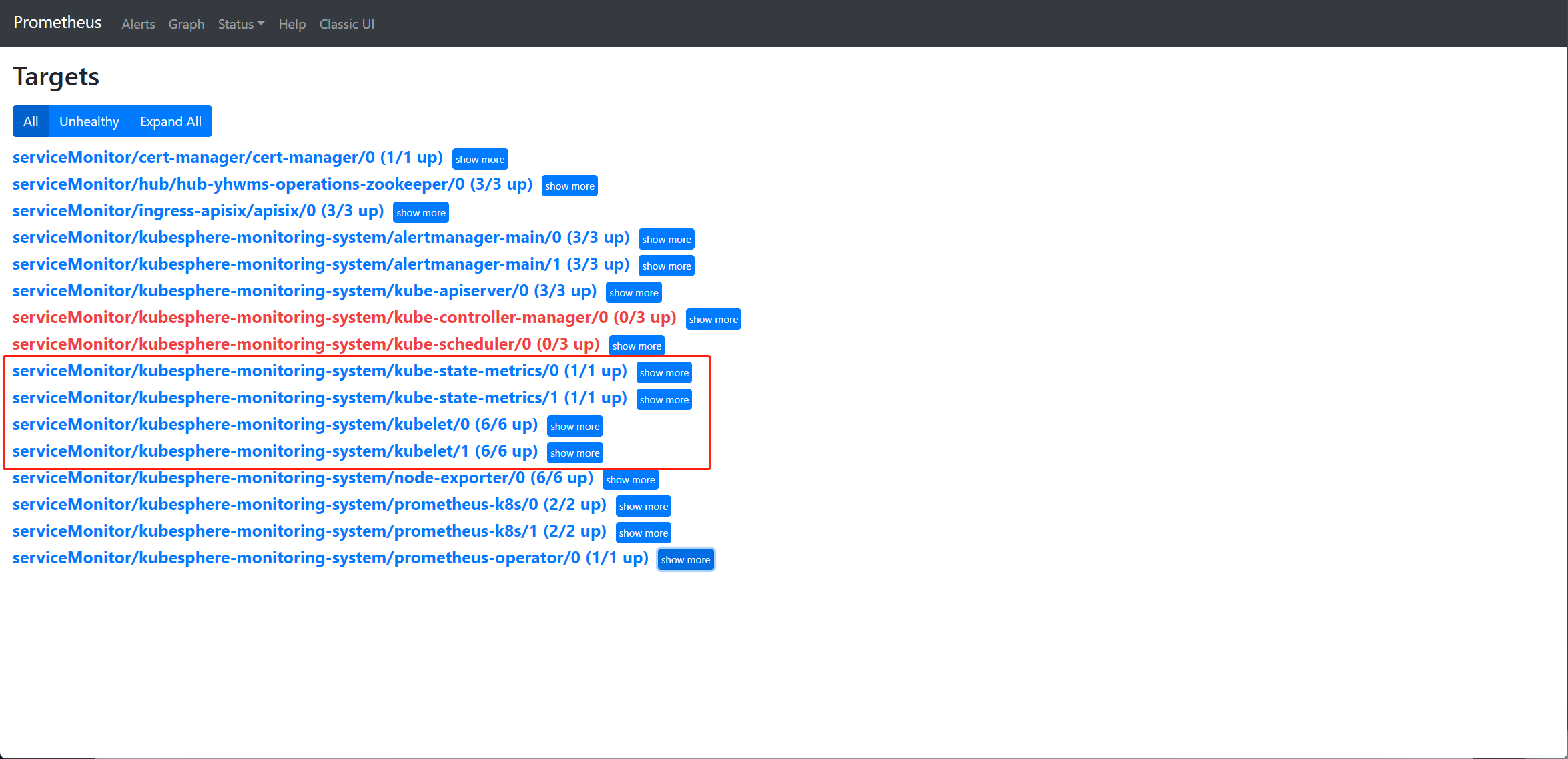
跟kubelet 与kube-state-metrics 多个采集项没关系,他们是不同的uri或端口。
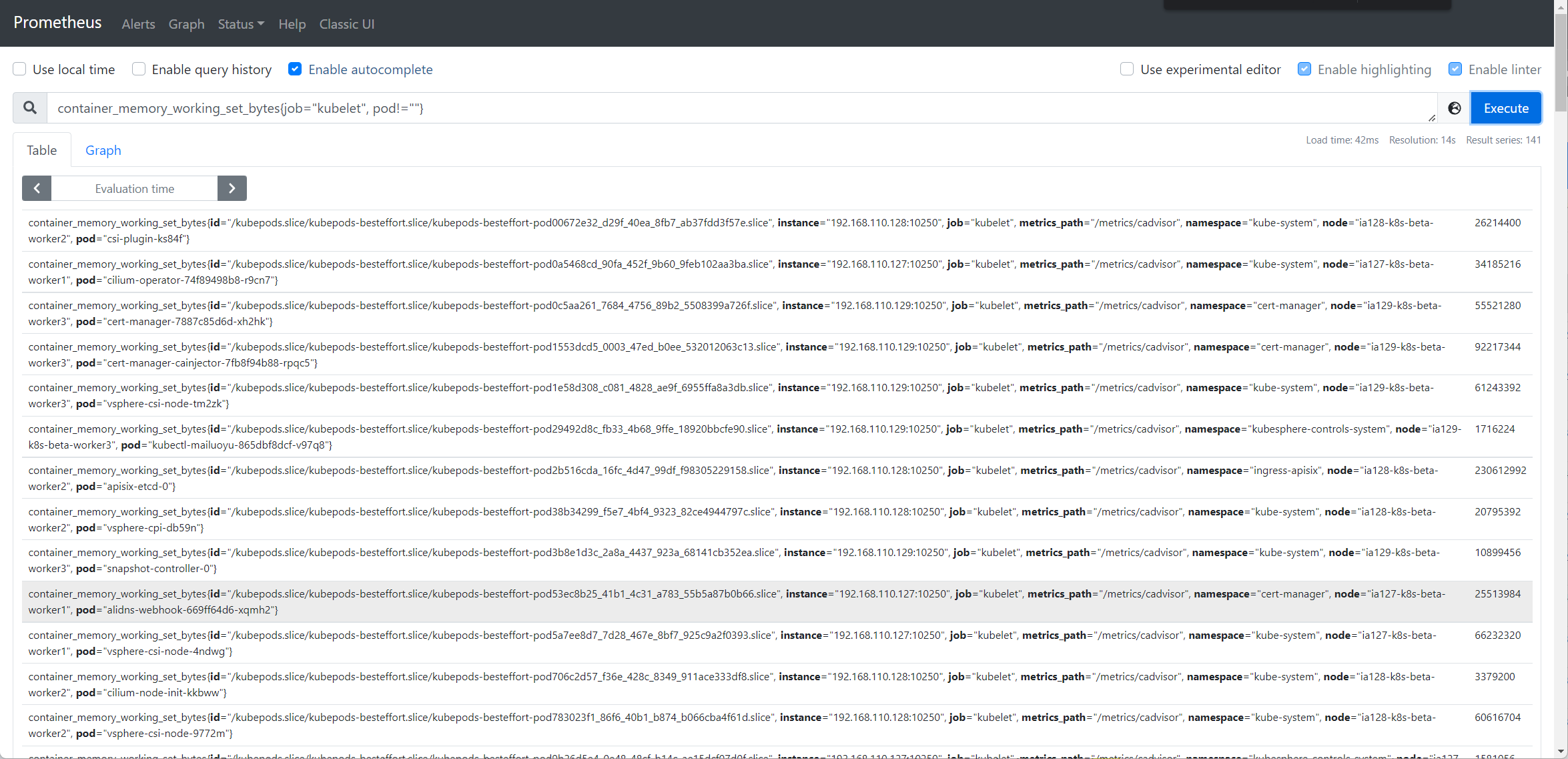
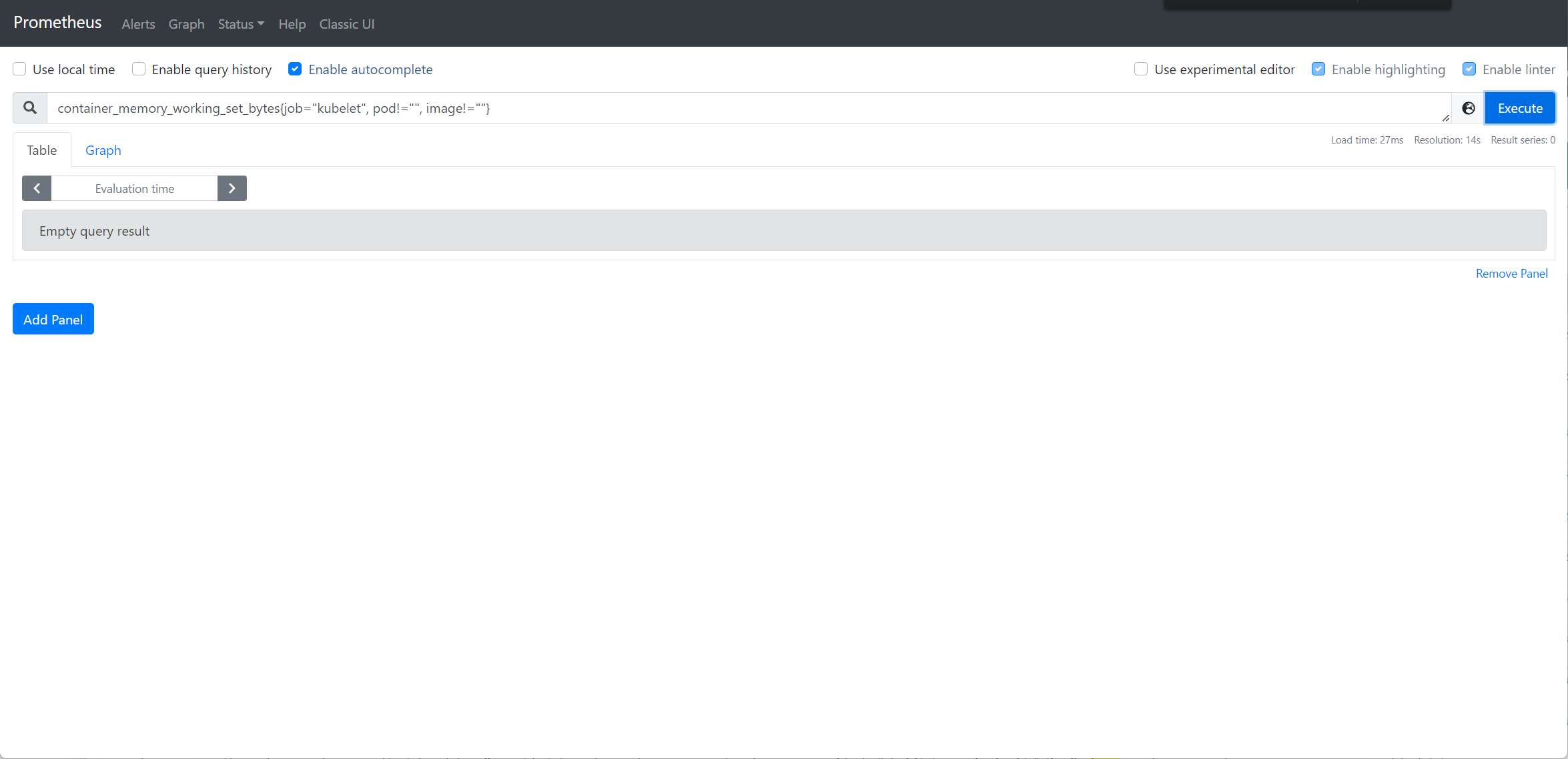
我们以Pod 资源使用页面中的内存使用为例,进行排查,他的promql 表达式为sum by (namespace, pod) (container_memory_working_set_bytes{job="kubelet", pod!="", image!=""}) * on (namespace, pod) group_left(owner_kind, owner_name) kube_pod_owner{} * on (namespace, pod) group_left(node) kube_pod_info{} 你可以在 Prometheus 上验证下看是否有数据,这里的数值其实就是pod 的内存使用监控。
若数据不正常,可再排查具体的指标,分别查询container_memory_working_set_bytes(来自于kubelet 的/metric/cadvisor) 及kube_pod_owner、kube_pod_info(来自于kube-state-metrics) 数据是否正常,进一步确认是采集哪里的指标除了问题;
若数据正常,看看prometheus 是否是多副本,是否其中一个副本有问题,导致界面截图与实际查询副本不一致等。