
@ZhangFugui 大佬可以帮忙看看吗
全新安装的 kubesphere 3.3.0 pod资源监控无指标

zhuyaguang 你的集群版本和部署工具跟我一样吗
 frezesK零S
frezesK零S
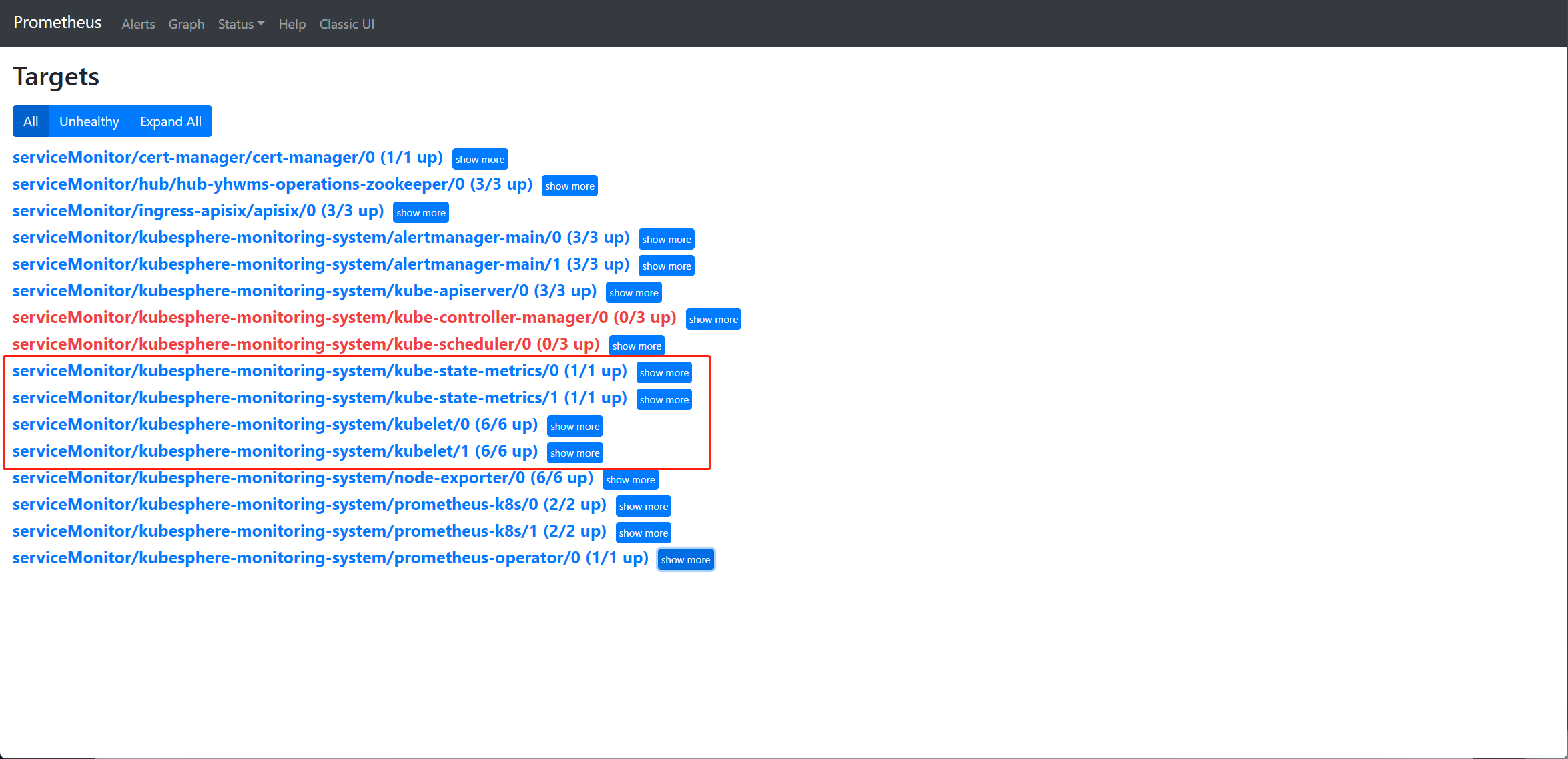
首先将 Prometheus 的 SVC 进行更改,允许直接外部访问,然后访问下 Prometheus 的页面,看看 Status/Target 中监控目标的监控情况,确认是什么原因导致unhealthy,针对原因进行排查。
然后根据你描述的现象,大概率是采集节点kubelet的metrics/cadvisor出现了问题,可以尝试重启下节点的kubelet。
- frezesK零S
- 已编辑
有两个重复的会是这个原因导致的吗
跟kubelet 与kube-state-metrics 多个采集项没关系,他们是不同的uri或端口。
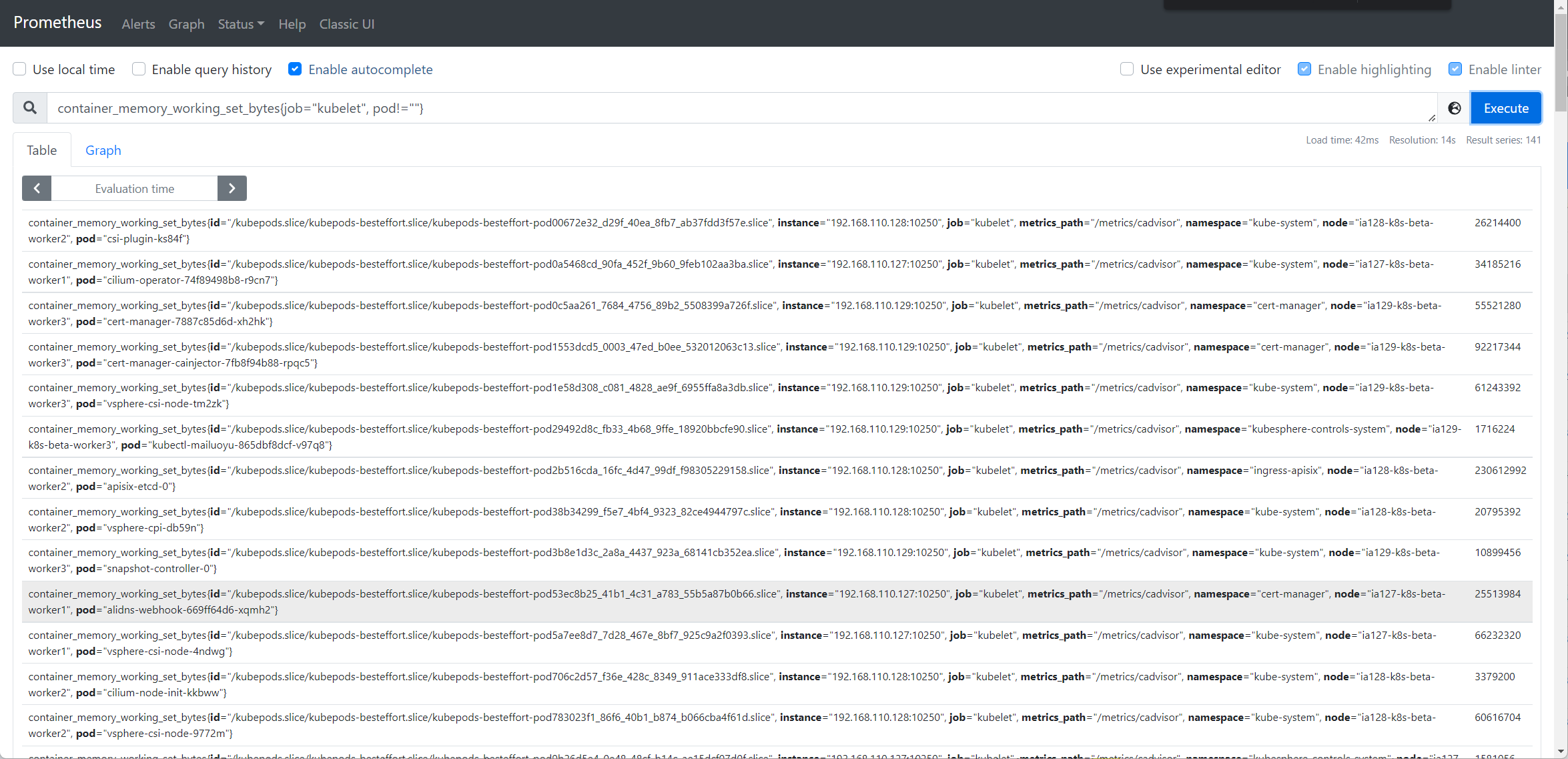
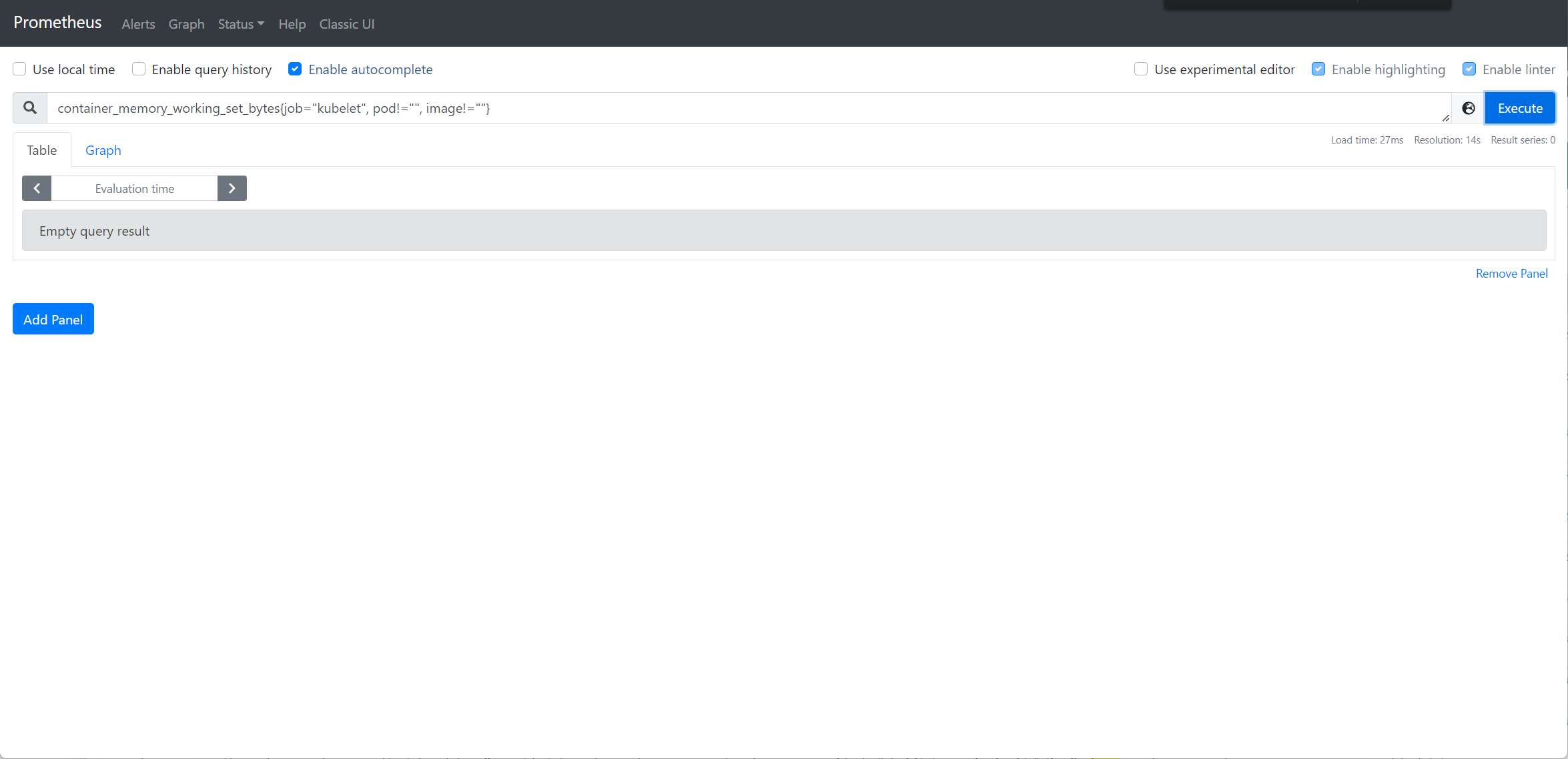
我们以Pod 资源使用页面中的内存使用为例,进行排查,他的promql 表达式为sum by (namespace, pod) (container_memory_working_set_bytes{job="kubelet", pod!="", image!=""}) * on (namespace, pod) group_left(owner_kind, owner_name) kube_pod_owner{} * on (namespace, pod) group_left(node) kube_pod_info{} 你可以在 Prometheus 上验证下看是否有数据,这里的数值其实就是pod 的内存使用监控。
若数据不正常,可再排查具体的指标,分别查询container_memory_working_set_bytes(来自于kubelet 的/metric/cadvisor) 及kube_pod_owner、kube_pod_info(来自于kube-state-metrics) 数据是否正常,进一步确认是采集哪里的指标除了问题;
若数据正常,看看prometheus 是否是多副本,是否其中一个副本有问题,导致界面截图与实际查询副本不一致等。
- frezesK零S
- 已编辑
麻烦详细提供下 containerd 的版本,kubernetes 版本,系统环境等。
检索相关 issue 好像是旧版 containerd 会有这个问题。可查阅google/cadvisor#2249.
- frezesK零S
k3s 上运行的? 参考下这个issue k3s-io/k3s#473