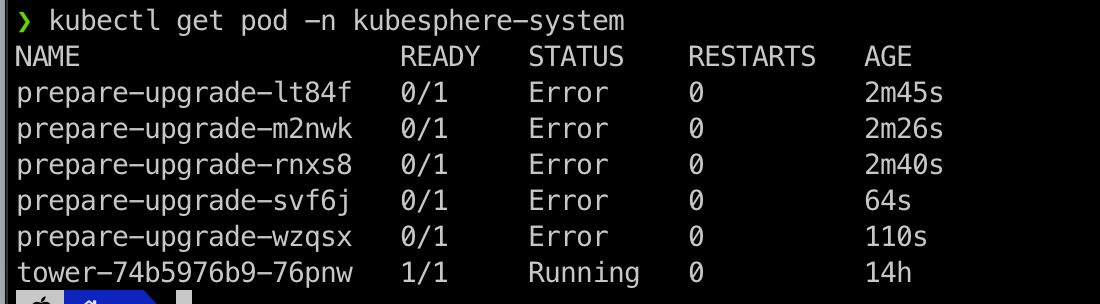
重新执行更新,还是报错, 我的电脑是mac M1 系列,跟客户是啥系统没关系吧,看这个报错,还是空指针,哪里不对
kubectl logs -f -n kubesphere-system prepare-upgrade-rnxs8
I0422 05:07:44.886017 1 filepath.go:71] [Storage] LocalFileStorage File directory /tmp/ks-upgrade already exists
I0422 05:07:44.886187 1 executor.go:158] [Job] whizard-alerting is disabled
I0422 05:07:44.886201 1 executor.go:158] [Job] whizard-logging is disabled
I0422 05:07:44.886205 1 executor.go:158] [Job] whizard-notification is disabled
I0422 05:07:44.886209 1 executor.go:158] [Job] tower is disabled
I0422 05:07:44.886212 1 executor.go:158] [Job] whizard-telemetry is disabled
I0422 05:07:44.886216 1 executor.go:158] [Job] whizard-events is disabled
I0422 05:07:44.886220 1 executor.go:158] [Job] kubefed is disabled
I0422 05:07:44.886224 1 executor.go:158] [Job] servicemesh is disabled
I0422 05:07:44.886227 1 executor.go:158] [Job] storage-utils is disabled
I0422 05:07:44.886240 1 executor.go:155] [Job] devops is enabled, priority 800
I0422 05:07:44.886261 1 executor.go:155] [Job] iam is enabled, priority 999
I0422 05:07:44.886272 1 executor.go:158] [Job] metrics-server is disabled
I0422 05:07:44.886276 1 executor.go:158] [Job] opensearch is disabled
I0422 05:07:44.886279 1 executor.go:158] [Job] whizard-monitoring is disabled
I0422 05:07:44.886287 1 executor.go:155] [Job] network is enabled, priority 100
I0422 05:07:44.886295 1 executor.go:158] [Job] vector is disabled
I0422 05:07:44.886304 1 executor.go:155] [Job] application is enabled, priority 100
I0422 05:07:44.886311 1 executor.go:155] [Job] core is enabled, priority 10000
I0422 05:07:44.886323 1 executor.go:155] [Job] gateway is enabled, priority 90
I0422 05:07:44.886327 1 executor.go:158] [Job] kubeedge is disabled
I0422 05:07:44.898462 1 helm.go:145] getting history for release [ks-core]
I0422 05:07:44.951846 1 validator.go:57] [Validator] Current release's version is v3.3.2
I0422 05:07:44.951869 1 executor.go:220] [Job] core prepare-upgrade start
I0422 05:07:44.951878 1 executor.go:58] [Job] Detected that the plugin core is true
I0422 05:07:44.977148 1 core.go:314] scale down deployment kubesphere-system/ks-apiserver unchanged
I0422 05:07:45.000332 1 core.go:314] scale down deployment kubesphere-system/ks-console unchanged
I0422 05:07:45.006025 1 core.go:314] scale down deployment kubesphere-system/ks-controller-manager unchanged
I0422 05:07:45.028711 1 core.go:314] scale down deployment kubesphere-system/ks-installer unchanged
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x18 pc=0x2025ccf]
goroutine 1 [running]:
kubesphere.io/ks-upgrade/pkg/jobs/core.(\*upgradeJob).deleteKubeSphereWebhook(0xc000a2f630, {0x2ba2f40, 0x40e7c00})
/workspace/pkg/jobs/core/core.go:429 +0x22f
kubesphere.io/ks-upgrade/pkg/jobs/core.(\*upgradeJob).PrepareUpgrade(0xc000a2f630, {0x2ba2f40, 0x40e7c00})
/workspace/pkg/jobs/core/core.go:118 +0xcc
kubesphere.io/ks-upgrade/pkg/executor.(\*Executor).PrepareUpgrade(0xc000491710, {0x2ba2f40, 0x40e7c00})
/workspace/pkg/executor/executor.go:227 +0x275
main.init.func5(0xc00021a800?, {0x26e5683?, 0x4?, 0x26e5687?})
/workspace/cmd/ks-upgrade.go:102 +0x26
github.com/spf13/cobra.(\*Command).execute(0x4095a80, {0xc000898420, 0x3, 0x3})
/workspace/vendor/github.com/spf13/cobra/command.go:985 +0xaaa
github.com/spf13/cobra.(\*Command).ExecuteC(0x4094c20)
/workspace/vendor/github.com/spf13/cobra/command.go:1117 +0x3ff
github.com/spf13/cobra.(\*Command).Execute(...)
/workspace/vendor/github.com/spf13/cobra/command.go:1041
main.main()
/workspace/cmd/ks-upgrade.go:136 +0x4e