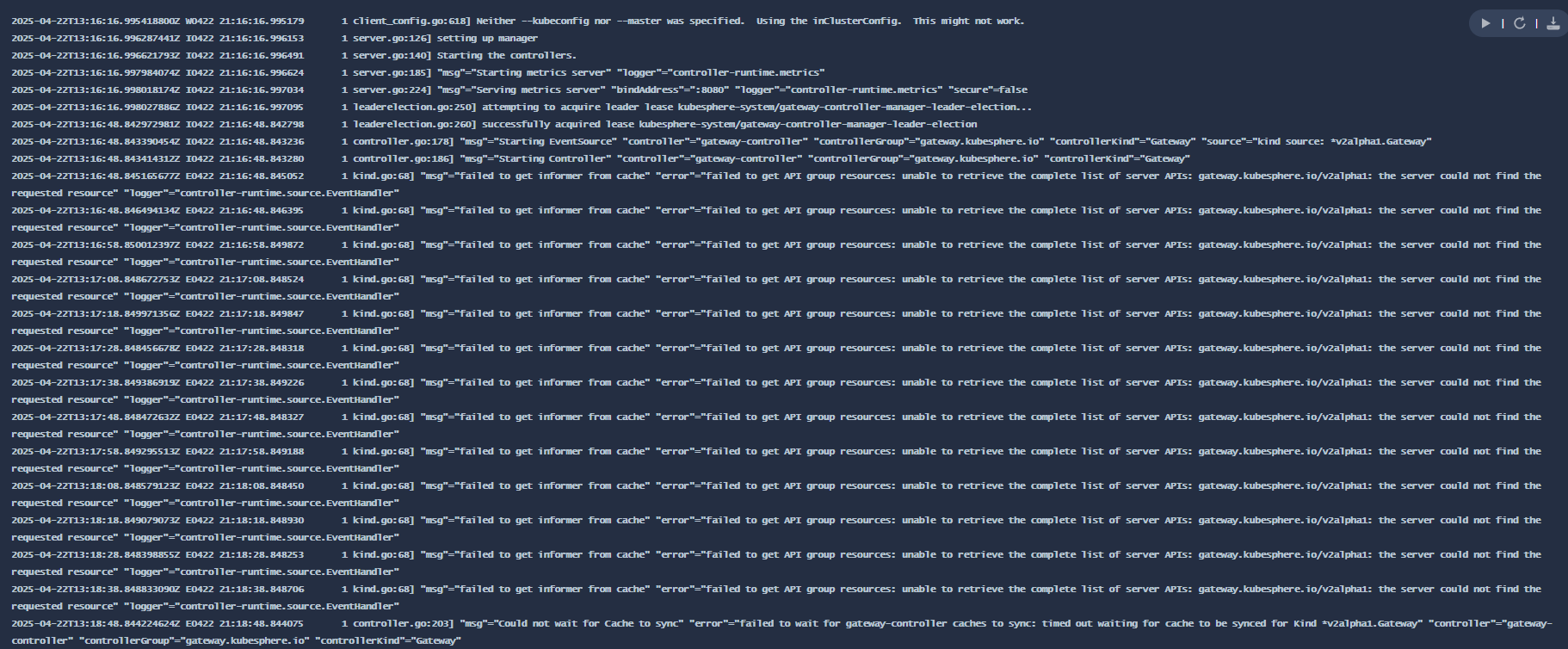
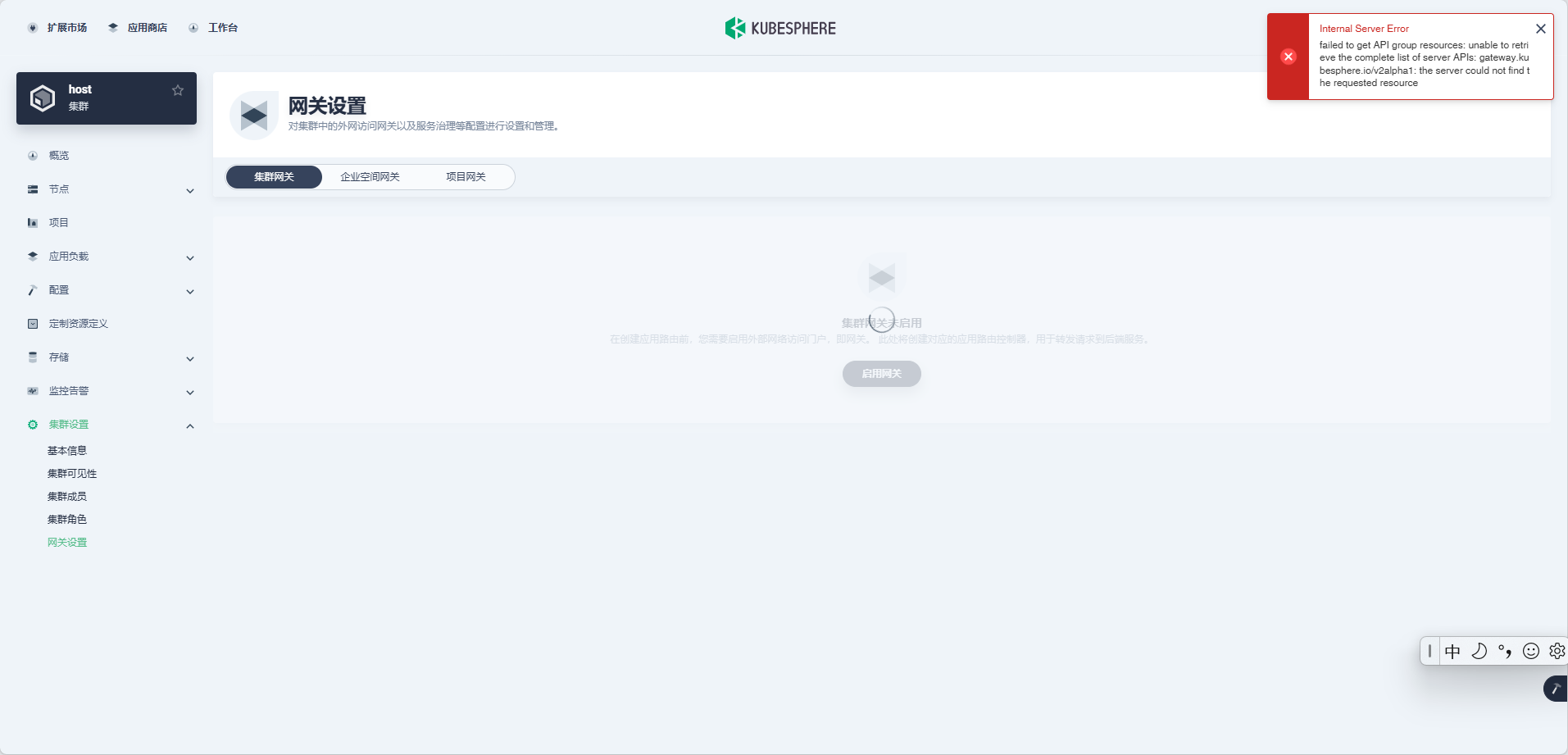
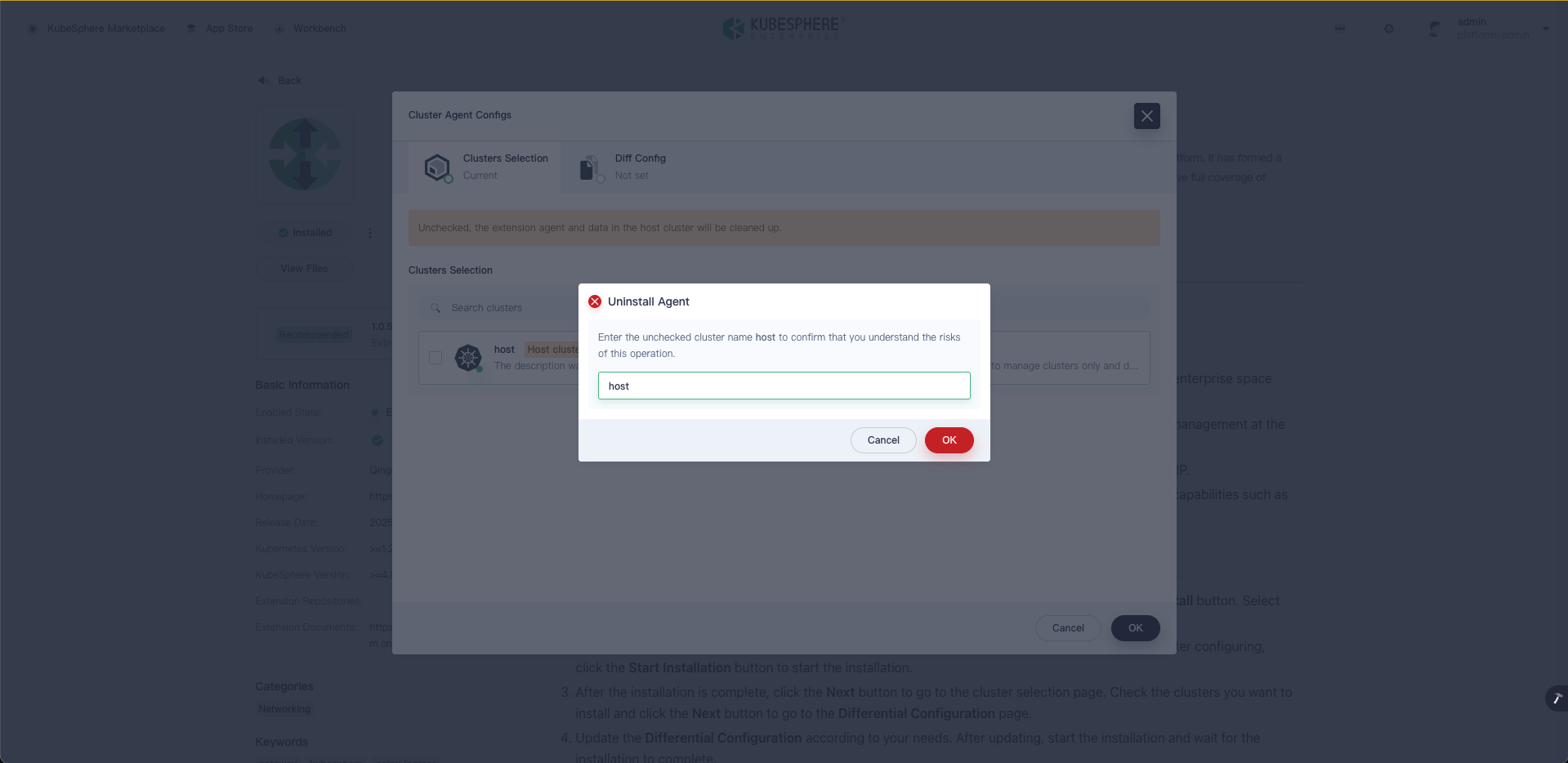
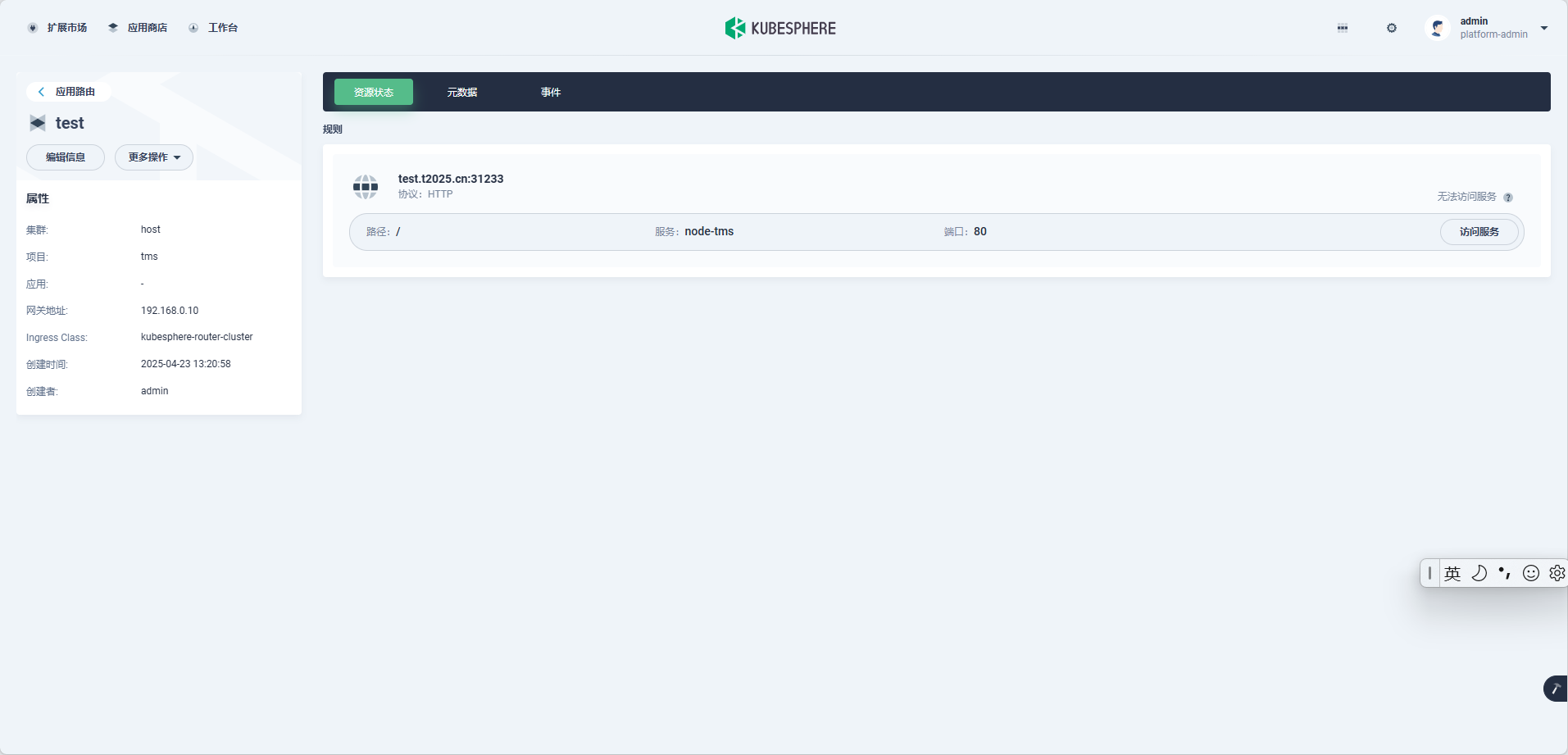
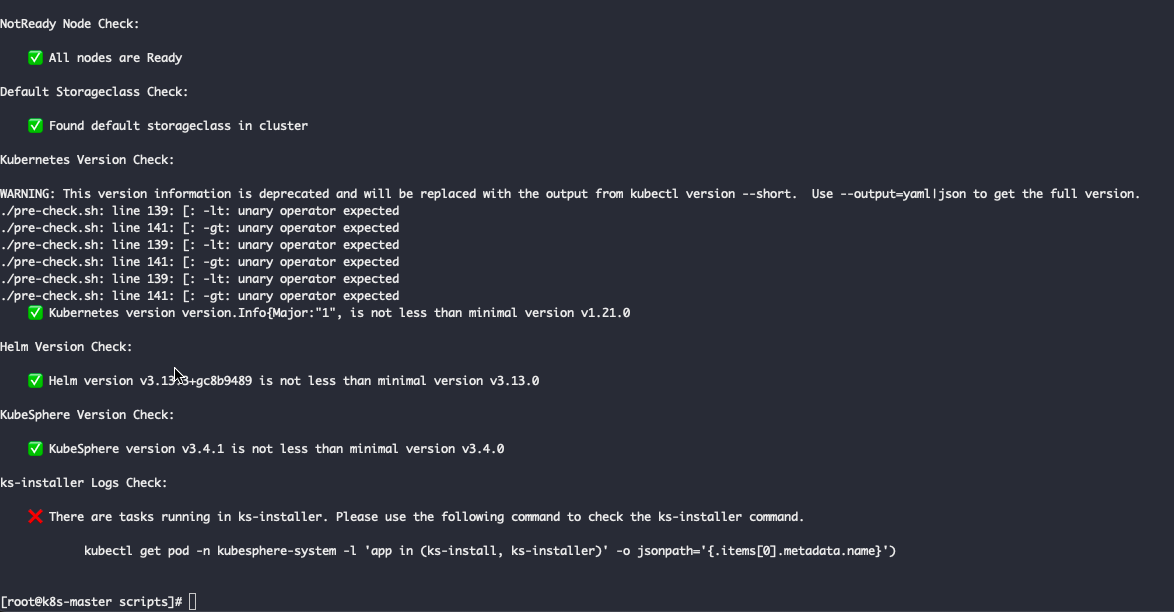
hongming 我看了日志报错,还是那个nil 要不然就需要删除 这些,但是我觉得还是跳过比较多,我尝试使用github 上制作镜像试试
kubectl get validatingwebhookconfigurations | grep kubesphere
cluster.kubesphere.io 1 19h
network.kubesphere.io 1 19h
resourcesquotas.quota.kubesphere.io 1 19h
rulegroups.alerting.kubesphere.io 3 19h
storageclass-accessor.storage.kubesphere.io 1 19h
users.iam.kubesphere.io 1 19h