hongmingK零SK壹S
hongmingK零SK壹S
是不是 retag 的时候搞错了,改了 imagePullPolicy也没拉到更新后的镜像,日志中的错误信息已经足够定位问题,你也可以自己去构建镜像试试。如果觉得麻烦,可以这么跳过,把导致异常的 validatingwebhook 先备份删除,升级完成后再恢复
hongmingK零SK壹S是不是 retag 的时候搞错了,改了 imagePullPolicy也没拉到更新后的镜像,日志中的错误信息已经足够定位问题,你也可以自己去构建镜像试试。如果觉得麻烦,可以这么跳过,把导致异常的 validatingwebhook 先备份删除,升级完成后再恢复
hongming tag 不应该的,毕竟后面的imageID 都是一致的, 把异常的validatingwebhook 备份删除,这个操作有点麻烦,咋跳过,咋跳过呢
hongmingK零SK壹S这个 imageID 看起来也是一致的,也是对的,但这是 x86 的,kubesphere/ks-upgrade 并没有提供 arm 镜像,你看看 prepare-upgrade 的 pod 实际拉取的是哪个呢,还有就是异常日志有没有变化,排除其它问题导致中断
hongming 我看了日志报错,还是那个nil 要不然就需要删除 这些,但是我觉得还是跳过比较多,我尝试使用github 上制作镜像试试
kubectl get validatingwebhookconfigurations | grep kubesphere
cluster.kubesphere.io 1 19h
network.kubesphere.io 1 19h
resourcesquotas.quota.kubesphere.io 1 19h
rulegroups.alerting.kubesphere.io 3 19h
storageclass-accessor.storage.kubesphere.io 1 19h
users.iam.kubesphere.io 1 19h
xingxing122 我拉取了master 分支,打的镜像还是有问题,这个问题修复是在那个分支搞的
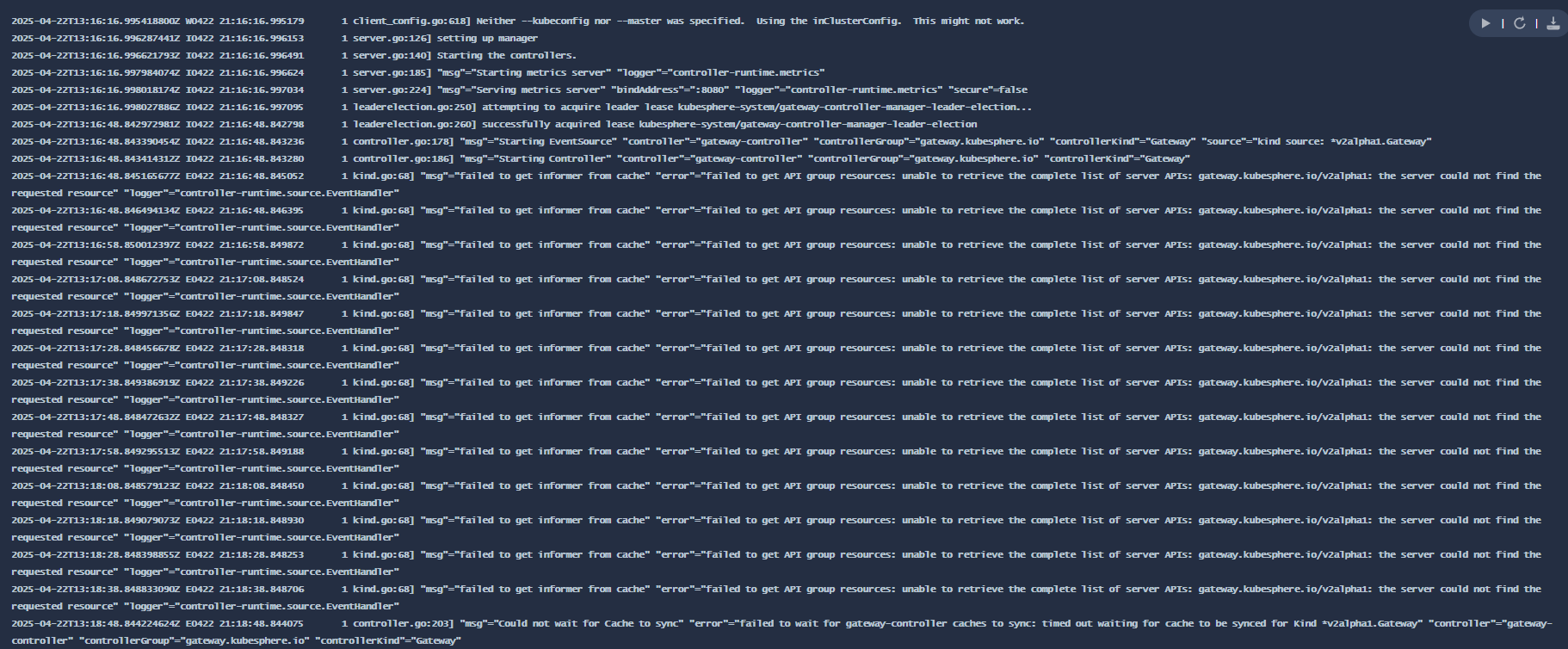
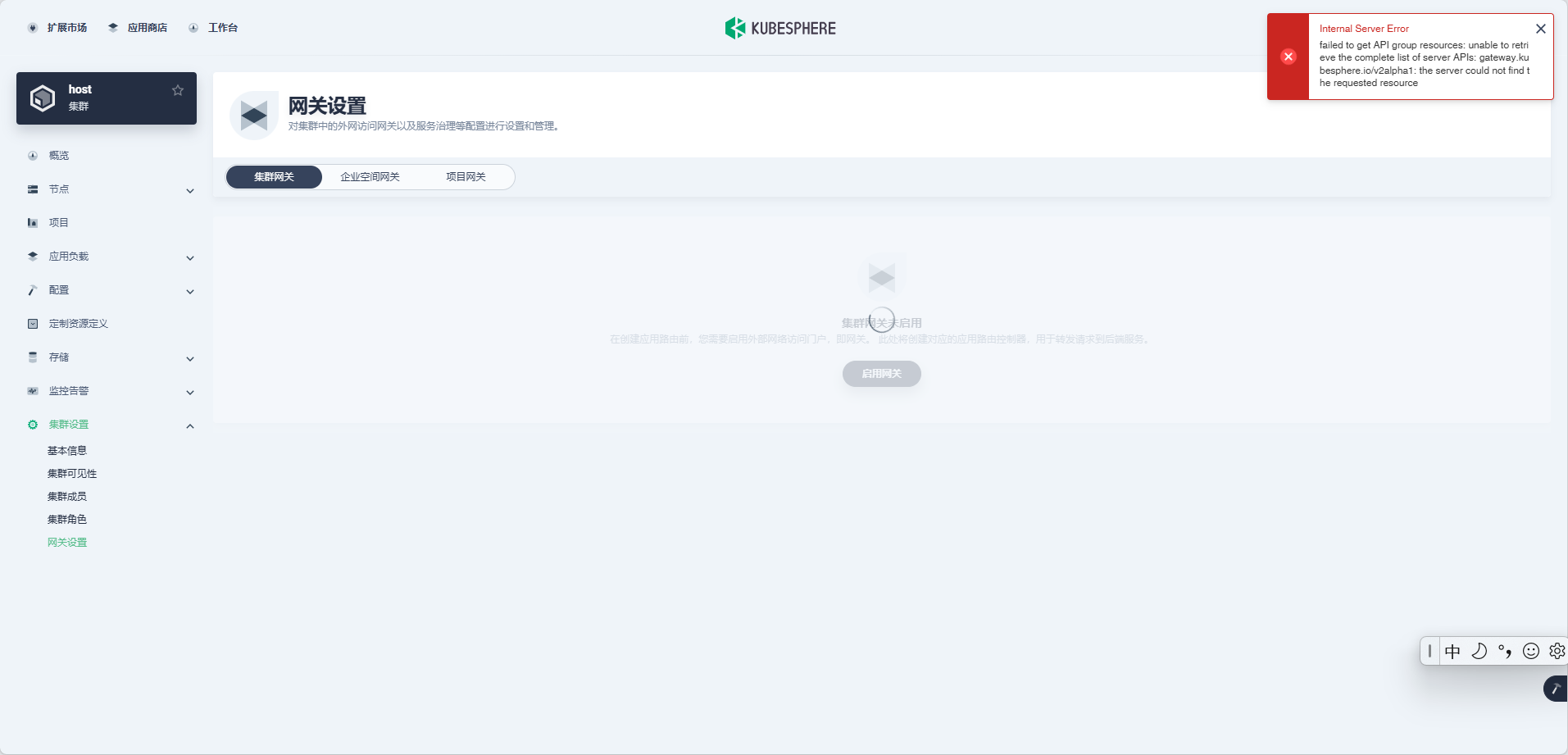
hongmingK零SK壹S升级网关 failed to get API group resources: unable to retrieve the complete list of server APIs: gateway.kubesphere.io/v2alpha1: the server could not find the requested resource
hongming 改动了,我拉去master 分支自己在本地打了一个镜像
hongmingK零SK壹S网关升级失败了,CRD 没被更新,可能是这个问题 kubesphere/ks-upgrade#28
可以检查一下 CRD 是否更新了
kubectl get crd gateways.gateway.kubesphere.io -o yaml重新部署一下 Gateway 扩展组件,把 CRD 重新创建一遍,再来升级网关实例
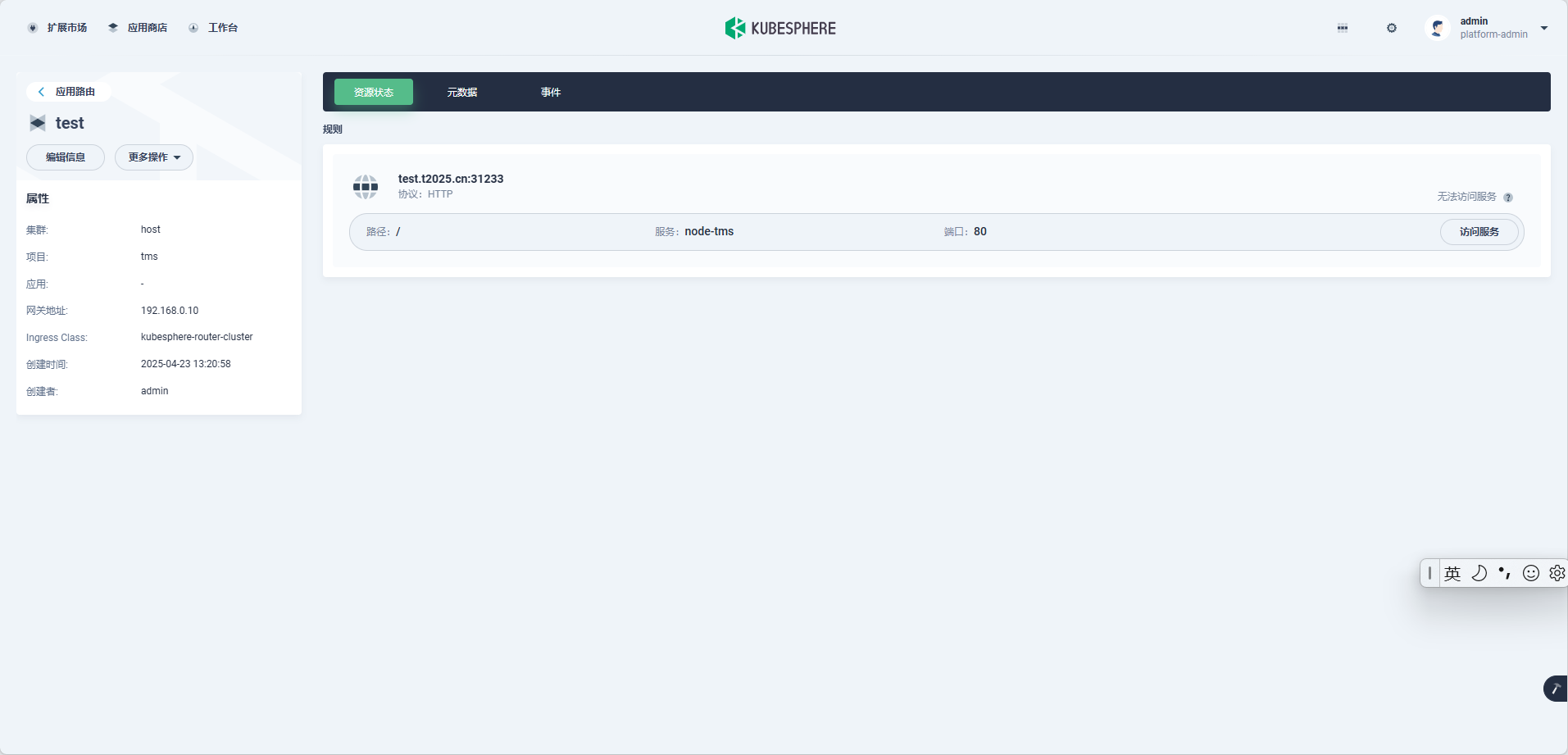
应用路由这里显示好像有问题,实际访问是没有端口的。
hongming 我现在都不会升级了,接下来都不知道咋操作了。 这个问题搞的有点懵逼
hongmingK零SK壹S还是检查 prepare upgrade pod 的日志,如果镜像正常更新了,就不可能继续在这一行空指针,
重新执行升级脚本,检查日志,重新核对错误信息
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x18 pc=0x2025ccf]
goroutine 1 [running]:
kubesphere.io/ks-upgrade/pkg/jobs/core.(\*upgradeJob).deleteKubeSphereWebhook(0xc000a2f630, {0x2ba2f40, 0x40e7c00})
/workspace/pkg/jobs/core/core.go:429 +0x22f运行pre-check.sh。控制台输出如下。查看ks-install的pod,也是在running状态。可以正常升级吗?
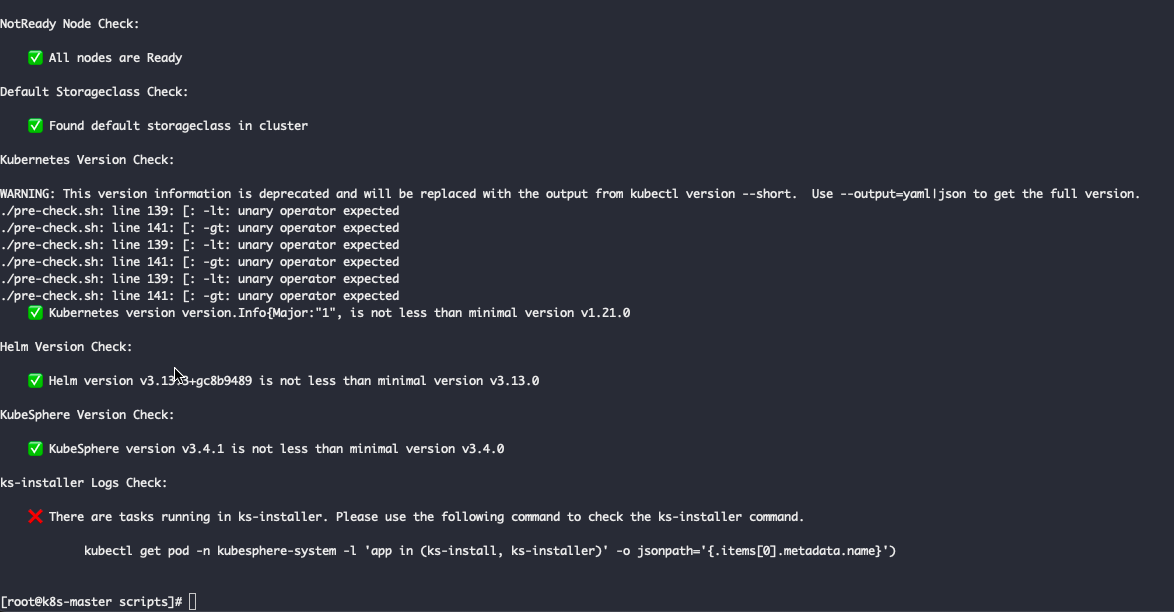
升级过程分为以下三个主要步骤,请按照顺序执行:
升级 host 集群并迁移扩展组件数据。
升级 member 集群并迁移扩展组件数据。
升级网关。
咨询一下,如果使用了其他的第三方网关,从3.4.0升级到v4.x不执行第3步。
大版本对网关有没有强依赖,升级会不会有影响?感谢。